机器学习之 TensorFlow 基础
在实现机器学习算法之前,让我们先熟悉如何使用 TensorFlow。
让我们做一个思想实验,看看在没有方便的计算库写 Python 代码会发生什么。假设你是一位私人企业主,负责跟踪你的产品的销售流程。你的库存包含 100 个不同的商品,你将所有商品的价格表示为一个向量 prices。另一个 100 维的向量 amonuts 是每件商品的数目。可以编写一个不导入任何库的 Python 代码来计算销售所有商品的收入。
1 | revenue = 0 |
仅仅计算两个向量的内积(点积)就需要这么多的代码。可以想象更复杂的东西(如,求解线性方程组或计算两个向量间的距离)需要的代码就更多了。
安装 TensorFlow 时,还会同时安装一个名为 NumPy 众所周知的健壮的 Python 库,该库有助于 Python 中数学操作。
下面代码片段展示了如何使用 NumPy 简洁地编写相同的内积代码。
1 | import numpy as np |
Python 是一种简洁的语言。这意味着这里不会有一大页一大页的神秘代码。另一方面,这也意味着在每行代码后面都会发生很多事情。
机器学习算法需要很多的数学运算。通常算法可以归结为简单函数的组合,它们迭代直至收敛。当然,你可以使用标准编程语言来执行这些步骤,但编写可管理和高性能代码的秘密是使用一个编写良好的库,如 TensorFlow。
TensorFlow 官方库参考手册
包含多种语言的 API 文档请参考TensorFlow API Documentation
因为机器学习依赖于数学公式,所以这里主要讲如何使用 TensoFlow 进行计算。这里的重点完全是关于如何使用 TensorFlow,而不是机器学习。
在后面,我们将使用 TensorFlow 的旗舰功能,这些功能对于机器学习至关重要。包括将计算表示为数据流图、设计和执行分离、部分子图计算和自动微分。无需多言,让我们开始吧!
确保 TensorFlow 正常工作
在开始之前,请依据需求参考官网安装说明安装 TensorFlow。
通过运行以下脚本导入 TensorFlow:
1 | import tensorflow as tf |
如果 Python 解释器没有报错,那么我们让准备开始使用 TensorFlow!
坚持 TensorFlow 约定
TensorFlow 通常以 tf 为限定名称导入。使用 tf 对 TensorFlow 进行限定是与其他开发人员和开源 TensorFlow 项目保持一致的好主意。
表示张量(tensor)
既然我们已经知道了如何将 TensorFlow 导入 Python 源文件,那么让我们开始使用它吧!描述现实世界中对象的一种方便方法是列出对象的属性或特性。例如,你可以按颜色、型号、发动机类型、里程等描述汽车。特征的有序列表称为特征向量(feature vector),这正是我们用 TensorFlow 代码中所表示的。
特征向量是机器学习中最有用的概念之一,因为它们的简单性(只是一个数字列表)。每个数据项通常由一个特征向量组成,而一个好的数据集有成百上千个这样的特征向量。毫无疑问,你经常会同时处理多个向量。一个矩阵可以简洁地表示一个向量列表,其中矩阵的每一列都是一个特征向量。
在 TensorFlow 中表示矩阵的语法是向量的向量,每个向量的长度相同。下图是一个两行三列矩阵的例子,注意,这是一个包含两个元素的向量,每个元素对应于矩阵的一行。
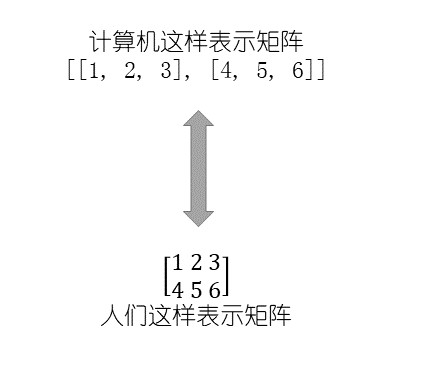
我们通过指定行和列的索引来访问矩阵中的元素。例如,第一行、第一列表示第一个左上角的元素。有时使用超过 2 个索引也是很方便的,如当涉及彩色图片时,我们使用红/绿/蓝通道而不是行列来描述像素。张量是矩阵的一种泛化,可以用任意数量的索引来指定一个元素。
张量是更多层的嵌套向量。例如,2×3×2 的张量是 [[1, 2], [3, 4], [5, 6]], [[7, 8], [9, 10], [ 11, 12]]],它可以被认为是两个大小为 3×2 的矩阵构成。因此,我们说这个张量的秩为 3。一般来说,张量的秩是指定一个元素所需的索引的数量。TensorFlow 中的机器学习算法作用于张量,因此真正理解如何使用它们非常重要。
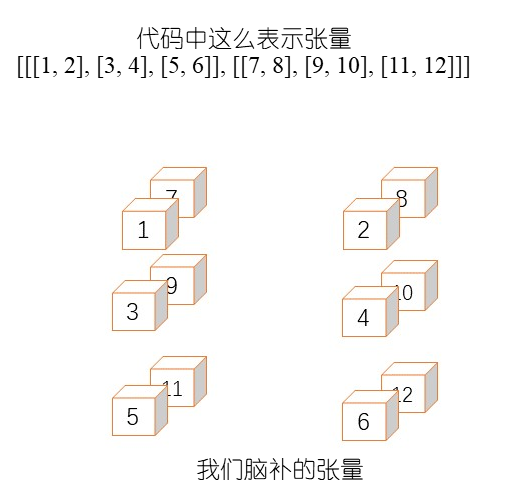
很容易在表示张量的方法上迷路。下面的代码片段试图用三种方法表示相同的 2×3 矩阵。该矩阵表示两个维度的两个特征向量。
1 | import tensorflow as tf |
#A我们将在 TensorFlow 中使用 NumPy 数组#B以 3 中不同的方式定义了 2×2 矩阵#C打印每个矩阵的类型#D将不同类型的矩阵转换为张量对象#E类型将会相同
第一个变量(m1)是一个列表,第二个变量(m2)是 NumPy 中的 ndarray,最后一个变量(m3)是我们使用 tf.constant 初始化的 TensorFlow 常量 Tensor 对象。
TensorFlow 中的所有运算符(例如负数)都是为张量对象而设计的。tf.convert_to_tensor(...) 是一个方便的函数,能够确保我们处理张量而不是其他类型。实际上,即使忘记了使用,TensorFlow 中的大多数函数也已经(冗余地)执行了此函数。使用 tf.convert_to_tensor(...) 是可选的,在这里展示它有助于揭开整个库处理隐式类型系统的神秘面纱。之前的代码片段输出以下结果三次:
1 | <class 'tensorflow.python.framework.ops.Tensor'> |
让我们再看看代码中定义张量。导入 TensorFlow 库后,我们可以使用 tf.constant 运算符,如下所示。这里有几个不同维度的不同张量。
1 | import tensorflow as tf |
#A定义一个 2×1 的矩阵#B定义一个 1×1 的矩阵#C定义一个秩为 3 的张量#D打印张量
运行代码产生以下输出:
1 | Tensor("Const:0", shape=(1, 2), dtype=float32) |
从输出中可以看出,每个张量都由恰当命名的 Tensor 对象表示。每个 Tensor 对象都有唯一的标签(名称)、维度(形状)以及数据类型(dtype)。由于我们没有明确提供名称,库自动生成名称:Const:0、Const_1:0 和 Const_2:0。
张量类型
请注意,m1 的每个元素都以小数点结尾。使用小数点可以告诉 Python,元素的数据类型不是整数,而是浮点数。我们可以向 TensorFlow 传入明确的 dtype 值,就像NumPy数组一样。
TensorFlow 还自带一些简单张量的便捷的构造函数。例如,tf.zeros(shape) 创建一个张量,其中所有值都初始化为指定形状的 0。类似地,tf.ones(shape) 创建一个指定形状的张量,其中所有值初始化为 1。 shape 参数是一个类型为 int32 的 1 维(1D)张量(即,整数列表),用来描述张量的维度。
练习 将一个 500×500 张量的所有元素初始化为 0.5。
答案 tf.ones([500, 500])*0.5
创建操作符
现在我们已经有几个可使用的张量了,我们可以应用更多有趣的操作符了(如,加法或乘法)。让我们从简单开始,对 m1 张量进行一个负操作(op, operation 的缩写)。
负矩阵将正数转换为相同幅度的负数,反之亦然。负操作是最简单的操作之一。如下面代码片段所示,负操作只需一个张量作为输入,并产生一个张量,其中每个元素都是相反的。
1 | import tensorflow as tf |
#A定义一个任意张量#B对张量取负#C打印对象
题外话 定义一个操作,例如负操作,与运行它不同。到目前为止,你已经学会定义操作。在下一节中,你将评估(或运行)它们以计算它们的值。
代码生成以下输出:
1 | Tensor("Neg:0", shape=(1, 2), dtype=int32) |
注意,输出并不是 [[ - 1, -2]]。这是因为我们打印的是负操作的定义,而不是负操作的实际运行结果。打印输出显示我们负操作是一个带名称、形状和数据类型的 Tensor 类。该名称已被自动分配,但在使用 tf.negative时,也可以显式地提供该名称。类似地,形状和数据类型可以从我们传入的 [[1, 2]] 推断出来。
有用的 TensorFlow 操作符
官方文件仔细列出了所有可用的数学运算。
常用操作符包括:tf.add(x, y)→ 两个相同类型的张量相加,x + ytf.subtract(x, y)→ 两个相同类型的张量相减,x - ytf.multiply(x, y)→ 两个张量逐元素相乘tf.pow(x, y)→ 逐元素求幂tf.exp(x)→ 等价于pow(e, x),其中 e 是欧拉数(2.718…)tf.sqrt(x)→ 等价于pow(x, 0.5)tf.div(x, y)→ 两个张量逐元素相除tf.truediv(x, y)→ 与tf.div相同,只是将参数强制转换为 floattf.floordiv(x, y)→ 与truediv相同,只是将结果舍入为整数tf.mod(x, y)→ 逐元素取余
练习 使用我们迄今所学的 TensorFlow 运算符产生高斯分布(也称为正态分布)。
答案 大多数数学表达式(如,*、-、+ 等)都是 TensorFlow 等价操作符的快捷方式,以便能够简洁的书写。高斯函数包含多种操作符,因此使用简写方式更为简洁,答案如下所示:
1 | from math import pi |
使用会话(session)执行操作符
会话是描述应该如何运行代码的软件系统环境。在 TensorFlow 中,会话设置硬件设备(如 CPU 和 GPU)之间的通信方式。这样,你可以设计你的机器学习算法而无需担心对硬件进行微管理。你可以配置会话以更改其行为,而不必更改机器学习代码。
要执行操作并检索其计算值,TensorFlow 需要一个会话。只有注册的会话才可以填充张量对象的值。为此,必须使用 tf.Session() 创建一个会话类并告诉它运行运算符(下面代码片段)。结果是可用于进一步计算的值。
1 | import tensorflow as tf |
#A定义一个任意张量#B在其上执行负操作#C开始一个会话以使能运行负操作#D告诉会话评估负矩阵#E打印结果
恭喜!你刚刚编写了你的第一个完整的 TensorFlow 代码。虽然它所做的只是在矩阵上执行负操作来生成 [[-1, -2]],但核心开销和框架与 TensorFlow 中的其他所有内容一样。会话不仅配置了在计算机上计算代码的位置,而且还设计了如何布局计算以便并行化。
代码性能似乎有点慢
你可能已经注意到,运行你的代码需要比预期要多几秒钟。TensorFlow 需要几秒钟来计算一个小小矩阵,这可能显得不太对劲。但是,为了优化库以实现更大更复杂的计算,需要进行大量的预处理。
每个 Tensor 对象都有一个 eval() 函数来评估定义其值的数学运算。但是,eval() 函数需要为库定义一个会话对象,以便了解如何最好地利用底层硬件。在上述代码中,我们使用了 sess.run(...),这相当于在会话上下文中调用 Tensor 的 eval() 函数。
当通过交互式环境(用于调试或演示目的)运行 TensorFlow 代码时,以交互模式创建会话通常更容易,会话是任何 eval() 调用的隐式部分。这样,会话变量不需要在整个代码中传递,这使得更容易关注算法的相关部分,如下面代码所示。
1 | import tensorflow as tf |
#A开始交互会话,使得 sess 变量不再需要在整个代码中传递#B定义一些任意矩阵,并进行取负操作#C现在可以评估负矩阵,而不必显式地指定会话#D打印负矩阵#E记得关闭会话,以释放资源
将代码理解为图
假设一位医生预测新生儿的预期体重为7.5磅。你想知道这与实际测量的重量有什么不同。。作为一个过度分析的工程师,你设计了一个函数来描述新生儿不同重量的可能性。例如,8 磅比 10 磅更可能。
你可以选择使用高斯概率分布函数。它将一个数字作为输入,并输出一个描述观察到的输入的概率。该函数始终在机器学习中显示,并且易于在 TensorFlow 中定义。它使用乘法、除法、减法和其他一些基本操作符。
将每个操作符都视为图中的一个节点。所以,只要你看到一个加号或其他任何数学概念,就把它看成是许多节点之一。这些节点之间的边代表数学函数的组成。具体来说,我们研究的负运算符是一个节点,且此节点的传入/传出边是张量变换的方式。张量(tensor)流过(flow)图,这就是为什么这个库被称为 TensorFlow !
每个运算符(操作符)都是一个强类型函数,它可以获取具有某种维度的输入张量并生成相同维度的输出张量。下图是使用 TensorFlow 设计高斯函数的一个例子,它被表示为一个图,其中操作符是节点,边是它们如何交互。整体而言,该图表示复杂的数学函数(高斯函数)。图表的小部分表示简单的数学概念,例如取负或倍增。
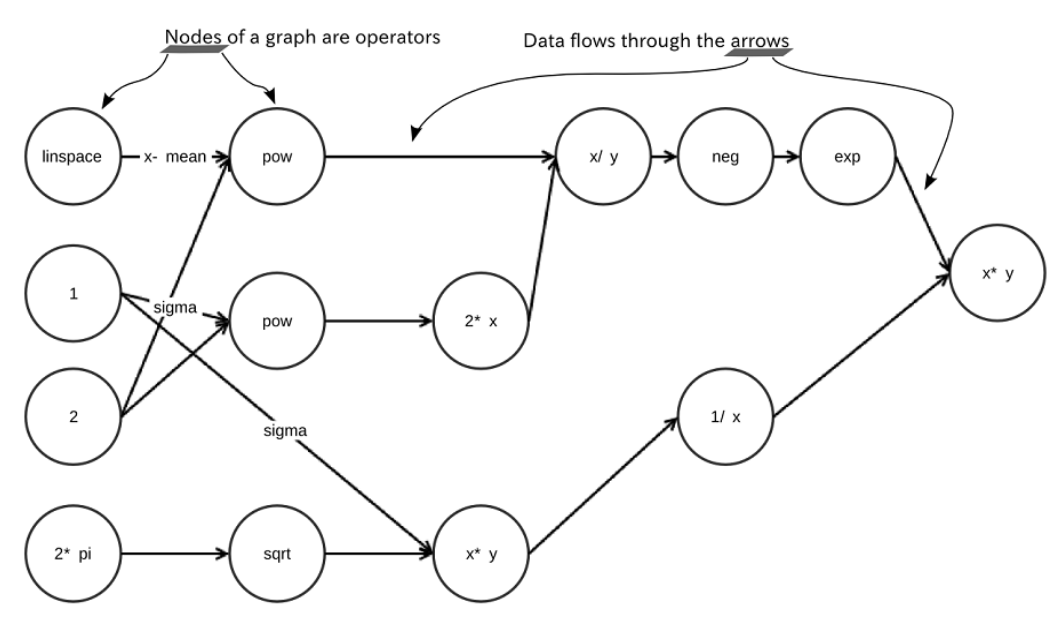
TensorFlow 算法易于可视化。它们可以简单地通过流程图来描述。这种流程图的技术术语是数据流图(dataflow graph)。数据流图中的每个箭头都称为边。另外,数据流图的每个状态都称为节点。会话的目的是将 Python 代码解释为数据流图,然后将图的每个节点的计算与 CPU 或 GPU 相关联。
会话配置
也可以给 tf.Session 传递选项。例如,TensorFlow 依据最佳方式自动给 CPU 或 GPU 设备分配操作(具体取决于可用的设备)。我们可以在创建一个会话时传递一个额外的选项 log_device_placements = True,如下面代码片段所示,它将展示计算在硬件上的确切发生的位置。
1 | import tensorflow as tf |
#A定义一个矩阵并取负#B开始一个会话,指定配置传入构造器以启用日志记录#C评估负矩阵#D打印结果
这会输出关于每个操作在会话中使用哪些 CPU/GPU 设备的信息。例如,运行代码会产生如下输出:
1 | Device mapping: |
会话在 TensorFlow 代码中非常重要。你需要调用一个会话来实际”运行“数学。下图展示了 TensorFlow 上的不同组件如何与机器学习管道交互。会话不仅运行图操作,还可以将占位符、变量和常量作为输入。到目前为止,我们已经使用了常量,但在后面,我们将开始使用变量和占位符。以下是这三种类型的值的简述。
占位符
未赋值的值,但无论它在何处运行,都将由会话初始化。通常,占位符是模型的输入和输出。
变量
可以更改的值,例如机器学习模型的参数。变量必须由会话初始化,然后才能使用。
常量
不会更改的值,例如超参数或设置项。
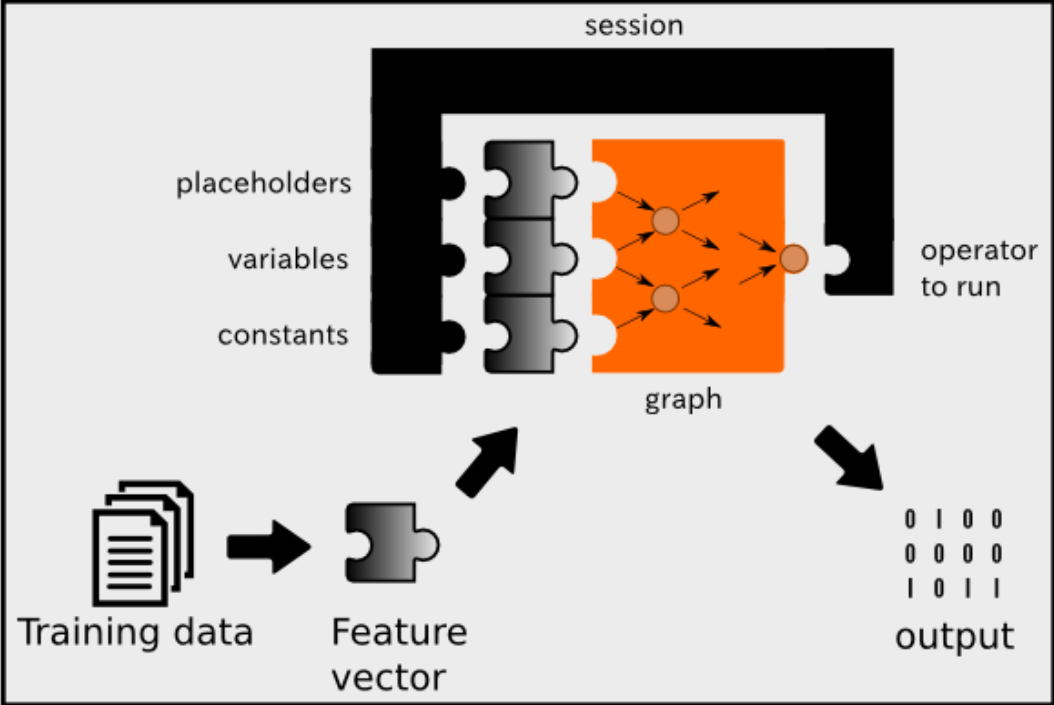
整个 TensorFlow 机器学习管道遵循上图的流程。TensorFlow 中的大部分代码都是关于设置图和会话的。一旦你设计了一个图并连接会话来执行它,你的代码就可以使用了!
在 Jupyter 中编写代码
由于 TensorFlow 首先是一个 Python 库,我们应该充分利用 Python 的解释器。Jupyter 是一个成熟的语言交互环境。它是一个网页应用程序,可以优雅地显示计算结果,以便与其他人共享带注释的交互式算法,以教授技术或演示代码。
你可以与其他人分享你的 Jupyter notebooks、交换想法并下载其他人的 notebook,以了解他们的代码。请参阅Installing Jupyter 以安装 Jupter。
从新终端中,将目录更改为想要练习 TensorFlow 代码的位置,然后启动 notebook 服务器。
1 | cd <to your TensorFlow stuff> |
运行先前的命令应该启动一个带有 Jupyter notebook 仪表板的新浏览器窗口。如果窗口没有自动打开,可以从任何浏览器手动导航到 http://localhost:8888 。

单击右上角标记为 New 的下拉菜单,在 Notebook 下,选择 Python 3,创建一个新 Notebook。这将创建一个名为 Untitled.ipynb 的新文件,可以立即通过浏览器界面开始编辑该文件。可以通过单击当前标题来更改该 Notebook 的名称,如可设为 TensorFlow Example Notebook。
Jupyter Notebook 中的所有内容都是独立的代码或文本块,被称为单元格(cell)。它们有助于将一长段代码分成可管理的代码片段和文档。可以单独运行单元格,也可以选择按顺序一次运行所有内容。有三种常用的运行单元格的方法:
- 在单元格上按下 Shift + Enter,执行单元格并高亮下一个单元格。
- 按下 Ctrl + Enter,执行单元格后将光标保持在当前单元格上。
- 按下 Alt + Enter,将执行单元格,然后在下面插入一个新的空单元格。
可以通过单击工具栏中的下拉菜单来更改单元格类型,如下图所示。或者,可以按 ESC 离开编辑模式,使用箭头键突出显示一个单元格,然后按 Y 键将其更改为编码模式或按 M 进入 markdown 模式。
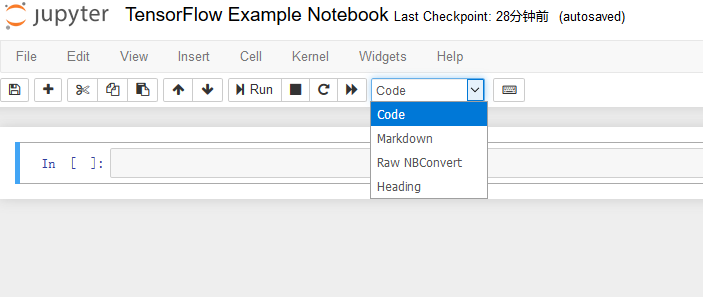
最后,我们可以创建一个 Jupyter Notebook,通过交错代码和文本单元格来优雅地演示一些 TensorFlow 代码。
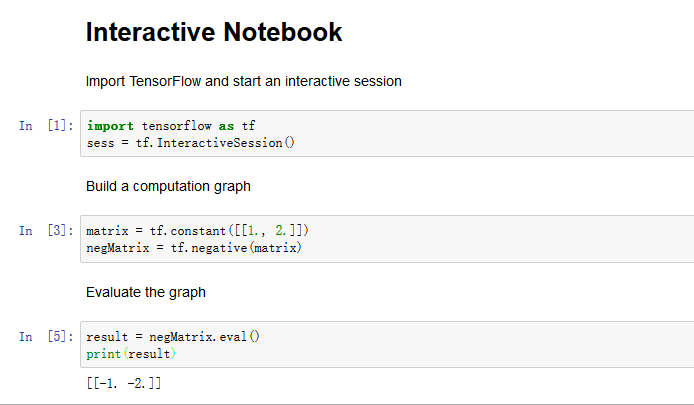
使用变量
使用 TensorFlow 常量是一个好的开始,但大多数有趣的应用都需要更改数据。例如,神经科学家可能对使用传感器检测神经活动感兴趣。神经活动的峰值可能是一个随时间变化的布尔变量。为了在 TensorFlow 中捕获该值,可以使用 Variable 类来表示一个值随时间变化的节点。
在机器学习中使用 Variable 的例子
找出能够最佳拟合多个点的方程是一个经典的机器学习问题。本质上,该算法从少数几个数字为特征(如,斜率、y 轴截距)的方程开始初始猜想,随着时间的推移,该算法不断为这些数字产生更好的猜测,这些数字也被称为参数。
到目前为止,我们只是在操纵常量。只有常量的程序对于实际应用来说并不是那么有趣,所以 TensorFlow 允许使用更丰富的工具,如变量,这些变量是可随时间变化值的容器。机器学习算法更新模型的参数,直到找到每个变量的最优值。在机器学习的世界中,参数波动直到最终稳定下来是很常见的,这使得变量成为他们优秀的数据结构。
下面的代码是一个简单的 TensorFlow 程序,演示了如何使用变量。当连续数据突然增加时,它会更新一个变量。考虑记录一段时间内神经元活动的测量结果。这段代码可以检测神经元活动突然发生的时间。
TensorFlow 允许我们使用 tf.InteractiveSession() 来声明一个会话。当你声明一个交互式会话时,TensorFlow 函数不需要 session 属性,它会使 Jupyter Notebook 中的编码更容易。
1 | import tensorflow as tf |
#A开始交互会话,使得 sess 变量不再需要在整个代码中传递#B假设我们的初始数据是这样的#C创建一个布尔变量 spike,用于检测数据的突增#D所有的变量都需要初始化#E遍历数据(跳过第一个数据),当有突增时更新 spike 变量#F通过使用tf.assign(<var name>, <new value>)给变量分配一个新的值来更新变量,评估变量看看是否有改变#G当不再使用会话时,记得关闭它
运行结果,如下所示:
1 | Spike False |
保存与加载变量
想象一下,编写一个代码块,但你想单独测试其中一小部分。在复杂的机器学习情况下,在已知检查点保存和加载数据使调试代码更得更容易。TensorFlow 提供了一个优雅的接口来保存和加载变量值到磁盘。
修改在上节中创建的代码,将 spike 数据保存到磁盘,以便可以将其加载到其他位置。我们将会把 spike 变量从简单的布尔值更改为捕获峰值历史数据的布尔值矢量。请注意,我们将明确地命名这些变量,以便稍后可以使用相同的名称加载它们。命名变量是可选的,但强烈建议使用,这会更好地组织代码。
1 | import tensorflow as tf |
#A启用交互会话#B假设我们的数据是这样的#C定义布尔向量 spikes,以定位突增#D别忘了初始化变量#Esaver 操作符将会保存和重载变量。如果没有向构造器中传入字典,则会保存当前程序中的所有变量#F遍历数据(跳过第一个数据),当有突增时更新 spike 变量#G使用tf.assign更新变量#H别忘了实际评估 updater,否则 spikes 不会更新#I将变量保存到硬盘#J打印保存变量的路径
你会注意到在源代码的同一目录中生成了一些文件,要检索这些数据,可以使用 saver 的 restore 函数,如下所示。
1 | import tensorflow as tf |
#A创建一个与保存的变量具有相同大小和名字的变量#B不再需要初始化,因为会直接载入#C创建 saver 操作符,以重载数据#D从文件中导入数据#E打印导入的数据
使用 TensorBoard 可视化数据
在机器学习中,最耗时的部分通常不是编程,而是等待代码完成运行。例如,有一个名为 ImageNet 的著名数据集,其中包含超过 1400 万个用于机器学习环境的图像。有时可能需要几天或几周才能完成使用大型数据集的算法的训练。TensorFlow 附带一个名为 TensorBoard 的便捷仪表板,用于快速浏览图中每个节点的值如何变化。这样,你就可以直观地了解代码的执行情况。
让我们看看我们如何在实际的例子中将变化趋势可视化。在下一节中,我们将在 TensorFlow 中实现移动平均(moving-average)算法,然后,我们将在 TensorBoard 中仔细跟踪我们关心的用于可视化的变量。
实现移动平均
在本节中,你将使用 TensorBoard 来可视化数据是如何变化的。假设你有兴趣计算某公司的平均股价。通常情况下,计算均值只是将所有值加起来除以所看到的总数,$Mean=(x_1 + x_2 + ... + x_n) / n$。当总数未知时,可以使用一种称为指数平均(exponential averaging)的技术来估计未知数量数据点的均值。指数平均算法将当前估算的均值当作一个函数,该函数将先前估算的均值和当前值作为输入。
更简洁地说,$Avg_t = f(Avg_{t-1}, x_t) = (1 - \alpha)Avg_{t-1} + \alpha x_t$。α(alpha)是要调节的参数,表示近期值在计算平均值时的强度。α 值越高,计算出的平均值就会与先前估计的平均值相差很大。
在编写代码时,最好考虑在每次迭代中发生的主要计算部分。在本例中,每次迭代将计算 $Avg_t = (1 - \alpha) Avg_{t-1} + \alpha x_t$。因此,我们可以设计一个 TensorFlow 运算符,它将完全按照公式执行。要实际运行这段代码,我们必须预定义 alpha,curr_value 和 prev_avg。
1 | update_avg = alpha * curr_value + (1 - alpha) * prev_avg #A |
#Aalpha 是tf.constant、curr_value 是占位符、prev_avg 是变量
我们稍后将定义未定义的变量。我们这样编写代码的原因是,通过首先定义接口,迫使我们实现外围代码以满足接口。让我们直接跳到会话部分,看看我们的算法应该如何运行。下面代码设置了主循环,并在每次迭代中调用 update_avg 运算符。update_avg 运算符取决于使用 feed_dict 参数提供的 curr_value。
1 | raw_data = np.random.normal(10, 1, 100) |
总体情况很清楚,因为所有剩下要做的就是写出未定义的变量。让我们填补空白,实现 TensorFlow 代码。
1 | import tensorflow as tf |
#A创建 100 个均值为 10 标准差为 1 的元素#B定义 alpha 为常量#C占位符就像一个变量,但值从会话中注入#D初始化先前平均值为 0#E一个接一个的更新平均值
移动平均的可视化
现在我们已经有一个移动平均算法的实现,让我们用 TensorBoard 可视化结果。使用 TensorBoard 进行可视化通常是分为两步。
- 首先,你必须选择出你真正关心的节点,使用
summary操作进行标记。 - 然后,对它们调用
add_summary来对将要写入磁盘的数据进行排队。
例如,假设我们有一个 img 占位符和一个 cost 操作符,如下面代码所示。你可以标记每个人(通过给他们一个名字,如 img 或 cost),以便它们能够在 TensorBoard 中可视化。我们将采用移动平均做类似的事情。
1 | img = tf.placeholder(tf.float32, [None, None, None, 3]) |
更一般地说,为了与 TensorBoard 进行通信,我们必须使用 summary 操作,它会生成一个由 SummaryWriter 来保存的更新到目录的序列化字符串。每当从 SummaryWriter 调用 add_summary 方法时,TensorFlow 都会将数据保存到磁盘,以供 TensorBoard 使用。
警告 不要经常调用 add_summary 函数!虽然这样做会产生更高分辨率的变量可视化效果,但它会以更多计算和稍慢的学习为代价。
运行以下命令将会在与此源代码相同的文件夹中,创建一个名为 logs 的目录
1 | mkdir logs |
运行 TensorBoard,将 logs 目录的位置作为参数传入:
1 | tensorboard --logdir=./logs |
打开浏览器并导航到 http://<your PC name>:6006,这是 TensorBoard 的默认 URL。下面代码显示了如何将 SummaryWriter 连接到你的代码。运行它并刷新 TensorBoard 以查看可视化。
1 | import tensorflow as tf |
#A为均值创建 summary 节点#B为所有值创建 summary 节点#C合并 summary,以便一起运行#D向 writer 传入logs目录#E可选的,允许你在 TensorBoard 中可视化计算图#F同时运行合并操作和 update_avg 操作#G将 summary 添加到 writer
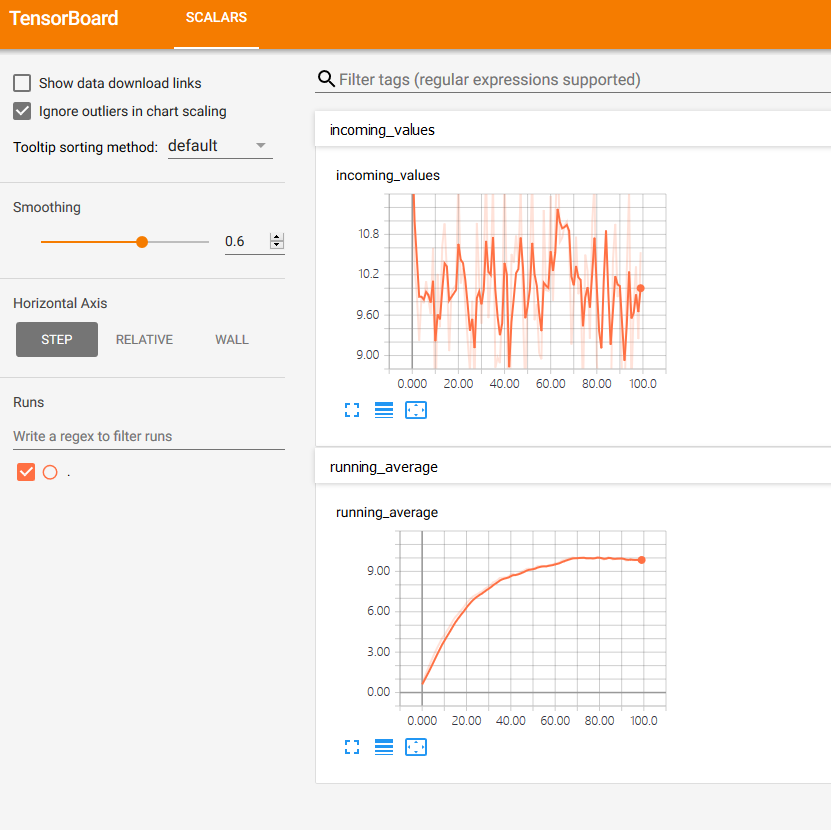
此外 启动 TensorBoard 之前,可能需要确保 TensorFlow 会话已结束。如果你重新运行上面的代码,则需要记住清除日志目录。