数值 Python: 求解方程
前面,我们讨论了一般的方法和技术,即基于数组的数值计算、符号计算和可视化。这些方法是科学计算的基石,构成了我们在处理计算问题时可以使用的基本工具集。
从这里开始,我们开始探索如何利用前面介绍的基本技术从应用数学和计算科学的不同领域解决问题。本章的主题是代数方程求解。这是一个广泛的课题,需要应用数学的多个领域的理论和方法。特别地,当讨论方程求解时,我们必须区分单变量和多变量方程。此外,我们需要区分线性和非线性方程。这种分类很有用,因为求解这些不同类型的方程需要应用不同的数学方法和途径。
我们从线性方程组开始,它非常有用,在科学的各个领域都有重要的应用。这种普遍性的原因是线性代数理论允许我们直接求解线性方程,而非线性方程一般难以求解,通常需要更复杂和计算要求更高的方法。由于线性系统易于求解,因此也是非线性系统局部逼近的重要工具。然而,线性化只能描述局部性质,对于非线性问题的全局分析需要其他技术。这种方法通常采用迭代方法来逐步构造解的越来越精确的估计。
在本章中,我们尽可能地使用 SymPy 来符号化地求解方程,并使用 SciPy 库中的线性代数模块来数值求解线性方程组。为了解非线性问题,我们将在 SciPy 的 optimize 模块中使用求根(root-finding)函数。
导入模块
在本章中,我们将使用 scipy.linalg 模块求解线性方程组,scipy.optimize 模块求解非线性方程
1 | from scipy import linalg as la |
在本章,我们还会使用 NumPy、SymPy 和 Matplotlib。
1 | import sympy |
为了在 Python2 和 Python3 中整除的行为表现一致,还需要以下语句:
1 | from __future__ import division |
线性方程组
线性代数的一个重要应用是求解线性方程组。
一般来说,线性方程组可以写成
$$
\begin{cases}
a_{11}x_{1} + a_{12}x_{2} + \cdots + a_{1n}x_{n}= b_{1} \
a_{21}x_{1} + a_{22}x_{2} + \cdots + a_{2n}x_{n}= b_{2} \
\vdots \quad \quad \quad \vdots \
a_{m1}x_{1} + a_{m2}x_{2} + \cdots + a_{mn}x_{n}= b_{m}
\end{cases}
$$
这是一个具有 m 个等式,n 个未知数 $\{x_1, x_2, ..., x_n\}$ 的线性方程组,其中 $a_{mn}$ 和 $b_m$ 是已知参数或常数。使用线性方程组时,用矩阵形式写出方程很方便:
$$
\begin{pmatrix}
a_{11} & a_{12} & \cdots & a_{1n} \
a_{21} & a_{22} & \cdots & a_{2n} \
\vdots & \vdots & \ddots & \vdots \
a_{m1} & a_{m2} & \cdots & a_{mn}
\end{pmatrix}
\begin{pmatrix}
x_1 \
x_2 \
\vdots \
x_n
\end{pmatrix} =
\begin{pmatrix}
b_1 \
b_2 \
\vdots \
b_m
\end{pmatrix}
$$
或者简单地 $Ax=b$,其中 $A$ 是 $m \times n$ 矩阵,$b$ 是 $m \times 1$ 矩阵(或 m-向量),$x$ 是未知的 $n \times 1$ 解矩阵(或 n-向量)。根据矩阵 $A$ 的性质,解向量 $x$ 可能存在也可能不存在,如果存在解,它不一定是唯一的。然而,如果存在解,则可以将其表示为向量 $b$ 与矩阵 $A$ 列向量的线性组合,其中系数由解向量 $x$ 中的元素给出。
若在方程组中 n < m ,则认为该系统是欠定的,因为它的方程数比未知数少,因此不能完全确定唯一的解。另一方面,如果 m > n,那么方程组就被认为是超定的。这通常会导致冲突约束,导致解不存在。
Square Systems
m = n 的 square systems 是一个重要的特例。它对应于方程数等于未知变量数的情况,因此它可能有一个唯一解。
为了存在唯一解,矩阵 $A$ 必须是非奇异的,在这种情况下存在 $A$ 的逆,并且解可写为 $x = A^{-1}b$。如果矩阵 $A$ 是奇异的,即矩阵的秩小于 $n$,$rank(A)< n$,或者等价地,如果其行列式为零,$det A = 0$,则方程 $Ax = b$ 无解或者有无穷多的解,这取决于右侧向量 $b$。矩阵 $rank(A) < n$ 时,其列或行可以表示为其他列或向量的线性组合,因此它们对应于不包含任何新约束的方程,且系统实际上是欠定的。因此,计算定义线性方程组的矩阵 $A$ 的秩是一种有用的方法,它可以告诉我们矩阵是否是奇异的,因此是否存在解。
当 $A$ 满秩时,可以保证解存在。但是,可能不能精确计算解。矩阵的条件数 $cond(A)$ 给出了衡量一个线性方程组好坏的条件。如果条件数接近 1,则说系统条件良置(well conditioned,条件数为 1 是理想条件),如果条件数很大,则系统条件病态(ill conditioned)。一个病态的线性方程组的解可能有很大误差。可以从一个简单的错误分析中获得关于条件数的直观解释。假设我们有一个形式为 $Ax=b$ 的线性方程组,其中 $x$ 是解向量。现在考虑 $b$ 的一个小变化,$\delta b$,由 $A(x+\delta x)=b+\delta b$ 给出解的相应变化 $\delta x$。由于方程的线性,我们有 $A\delta x = \delta b$。现在要考虑的一个重要问题是:与 $b$ 的变化相比,$x$ 的变化大吗?数学上我们可以用这些向量的范数之比来表述这个问题。具体而言,我们比较 $\lVert \delta x \rVert / \lVert x \rVert$ 和 $\lVert \delta b \rVert / \lVert b \rVert$,其中 $\lVert x \rVert$ 表示 $x$ 的范数。使用矩阵范数关系 $\lVert Ax \rVert \le \lVert A \rVert \cdot \lVert x \rVert$,我们可以写为
$$\frac{\lVert \delta x\rVert}{\lVert x \rVert} = \frac{\lVert A^{-1} \delta b \rVert}{\lVert x \rVert} \le \frac{\lVert A^{-1} \rVert \cdot \lVert \delta b \rVert}{\lVert x \rVert} = \frac{\lVert A^{-1} \rVert \cdot \lVert b \rVert}{\lVert x \rVert} \cdot \frac{\lVert \delta b \rVert}{\lVert b \rVert} \le \lVert A^{-1} \rVert \cdot \lVert A \rVert \cdot \frac{\lVert \delta b \rVert}{\lVert b \rVert}$$
因此,给定 $b$ 向量的相对误差,解 $x$ 的相对误差界限为 $cond(A) = \lVert A^{-1} \rVert \cdot \lVert A \rVert$,这就是矩阵 $A$ 的条件数。这意味着对于病态的线性方程组来说,即使 $b$ 向量中的小扰动可以使解向量 $x$ 出现大的误差。这在使用浮点数的数值解中尤其需要注意,因为浮点数仅是实数的近似值。因此,当求解线性方程组时,重要的是查看条件数来估计解的精度。
在 SymPy 中符号矩阵的秩、条件数以及范数可以使用 Matrix 的方法 rank、condition_number 和 nrom 计算。对于数值问题可以使用 NumPy 的函数 np.linalg.matrix_rank、np.linalg.cond 和 np.linalg.norm 计算。考虑下列 2 个线性方程:
$$
\begin{align}
2x_1 + 3x_2 & = 4 \
5x_1 + 4x_2 & = 23
\end{align}
$$
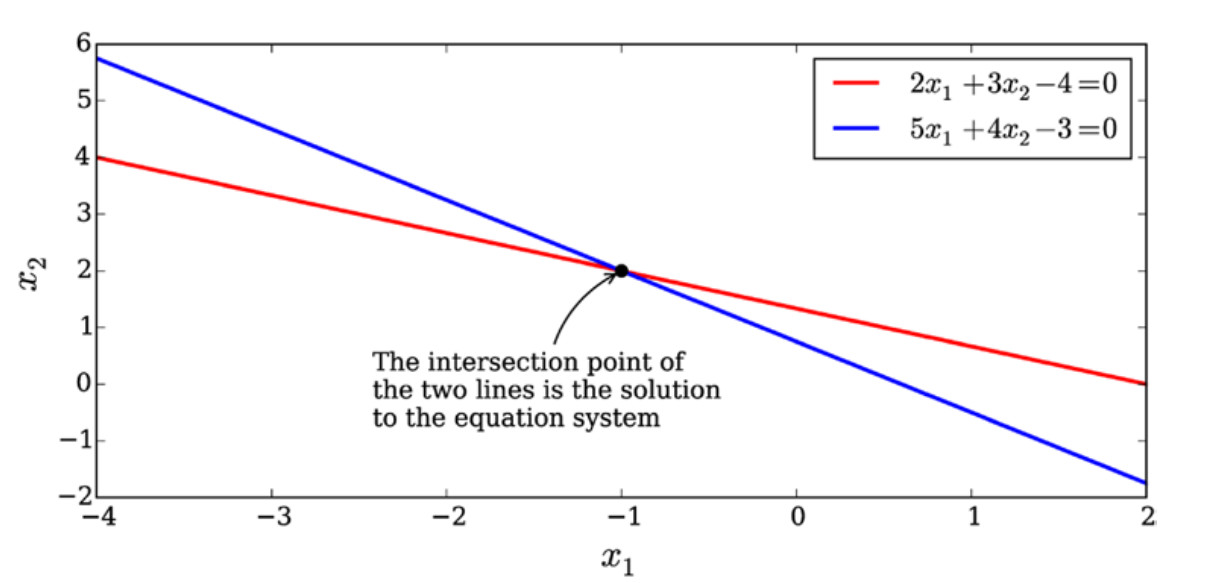
这两个方程对应于 $(x_1, x_2)$ 平面中的线,它们的交点是方程组的解。 从下图可以看出,这两条线对应于两个方程,这些线在 (-1, 2) 处相交。
1 | In [3]: A = sympy.Matrix([[2, 3], [5, 4]]) |
解线性问题的直接方法是计算矩阵 A 的逆矩阵,并将其与向量 b 相乘。但是,这不是求解解向量 x 最有效的计算方法。更好的方法是矩阵 A 的 LU 分解,使得 AL=U,其中 L 是下三角矩阵,U 是上三角矩阵。给定 L 和 U,可以通过首先用正向替换求解 Ly=b,然后用逆向替换求解 Ux=y 来有效地构造解向量 x。由于 L 和 U 是三角矩阵,这两个过程是计算高效的。
在 SymPy 中,我们可以使用 sympy.Matrix 类的 LUdecomposition 方法进行符号 LU 分解。此方法返回 L 和 U 矩阵以及行交换矩阵。当我们求解方程组 Ax = b 时,我们不需要明确计算 L 和 U 矩阵,而是使用 LUsolve 方法,该方法在内部执行 LU 分解,并使用这些因子求解方程组。回到前面的例子,我们可以使用以下公式求解方程组:
1 | In [16]: A = sympy.Matrix([[2, 3], [5, 4]]) |
对于数值问题,我们可以使用 SciPy 的线性代数模块的 la.lu 函数。它返回置换矩阵 P 、L 和 U 矩阵,使得 A=PLU。与 SymPy 类似,我们可以通过使用 la.solve 函数(它将 A 矩阵和 b 向量作为参数)显式地计算 L 和 U 矩阵来求解线性组 Ax=b。这通常是使用 SciPy 求解数值线性方程组的首选方法。
1 | In [35]: A = np.array([[2, 3], [5, 4]]) |
使用 SymPy 的优点当然是我们可以获得确切的结果,并且我们还可以在矩阵中包含符号变量。但是,并非所有问题都可以符号化地解决,有些问题可能会给出非常长的结果。另一方面,使用 NumPy/SciPy 的数值方法的优点是我们可以保证获得结果,但由于浮点误差,它是近似解。下面的代码说明了符号方法和数值方法之间的差异,也说明了数值方法可能对具有大的条件数的方程组敏感。在这个例子中,我们解方程组
$$
\begin{pmatrix}
1 & \sqrt{p} \
1 & \frac{1}{\sqrt{p}}
\end{pmatrix}
\begin{pmatrix}
x_1 \
x_2
\end{pmatrix} =
\begin{pmatrix}
1 \
2
\end{pmatrix}
$$
其对于 p = 1 是奇异的,而对于 1 附近的 p 是病态的。使用 SymPy,很容易找到解是:
1 | In [50]: p = sympy.symbols('p', positive=True) |
1 | from scipy import linalg as la |
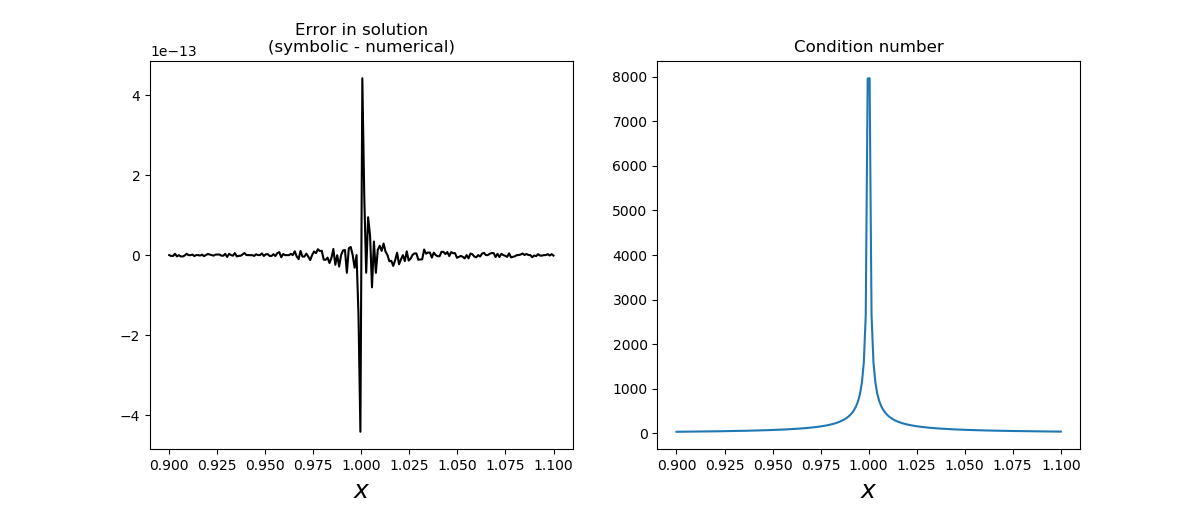
下图给出了这种符号解与数值解的比较。这里的数值解中的误差是由于数值浮点误差造成的,并且在系统具有大的条件数的情况下,在 p = 1 附近的数值误差显着更大。另外,如果在 A 或 b 中存在其他误差源,x中的相应误差可能会更加严重。
Rectangular Systems
对于 $m \neq n$ 的 rectangular Systems,它可以是欠定的也可以是超定的。欠定系统具有比等式数更多的变量数,因此解不能完全确定。对于这样一个系统,解必须以剩下的自由变量的形式给出,使得难以用数值方法来处理这类问题,但通常可以使用符号方法代替。
例如,考虑欠定线性方程组
$$
\begin{pmatrix}
1 & 2 & 3 \
4 & 5 & 6
\end{pmatrix}
\begin{pmatrix}
x_1 \
x_2 \
x_3
\end{pmatrix} =
\begin{pmatrix}
7 \
8
\end{pmatrix}
$$
这里我们有三个未知变量,但只有两个方程约束。通过将该方程写为 $Ax - b = 0$,我们可以使用 SymPy 的 sympy.solve 函数来获得(由剩下的自由变量 $x_3$ 表示)$x_1$ 和 $x_2$ 的解:
1 | In [73]: x_vars = sympy.symbols('x_1, x_2, x_3') |
这里我们得到了符号解 $x_1=x_3-19/3$ 和 $x_2=-2x_3+20/3$,它定义了 $\{x_1, x_2, x_3\}$ 所在的三维空间中的直线。因此这条线上的任何点都满足这个欠定方程组。
另一方面,如果系统超定,具有比未知数更多的方程数,自由度比约束多,通常对于这样的系统没有精确的解。然而,找超定系统的近似解通常是很有趣的。出现这种情况的一个例子是数据拟合:假设我们有一个模型,其中变量 y 是变量 x 中的二次多项式,$y = A + Bx +Cx^2$,且我们希望使用该模型拟合实验数据。这里,y 在 x 中是非线性的,但 y 在三个未知系数 A、B 和 C 中是线性的,依据这个事实可以将该模型写成线性方程组。如果我们采集了 m 对(变量 x 和 y 的数据) $\{( x_i, y_i )\}_{i=1}^m$,我们可以将模型写成 $m \times 3$ 的方程组:
$$
\begin{pmatrix}
1 & x_1 & x_1^2 \
\vdots & \vdots & \vdots \
1 & x_m & x_m^2
\end{pmatrix}
\begin{pmatrix}
A \
B \
C
\end{pmatrix} =
\begin{pmatrix}
y_1 \
\vdots \
y_m
\end{pmatrix}
$$
如果 m = 3,假设系统矩阵是非奇异的,我们可以求解未知模型参数 A、B 和 C。然而,直观上清楚的是,如果数据有噪声,那么我们使用三个以上的数据点,应该能够获得对模型参数更准确的估计。
然而,对于 m > 3,通常没有确切的解,我们需要引入一个近似解,以便为超定系统提供最佳拟合。对于超定系统 $Ax \approx b$,最适合的自然定义是:最小化平方误差之和,$\underset{x}{\operatorname{min}} \sum_{i=1}^m(r_i)^2$ ,其中 r=b-Ax 是残差向量。这产生了问题 $Ax \approx b$ 的最小二乘解(least square ),使得数据点与线性解之间的距离最小。在 SymPy 中,我们可以使用 solve_least_squares 方法求解超定系统的最小二乘解,对于数值问题,我们可以使用 SciPy 的函数 la.lstsq。
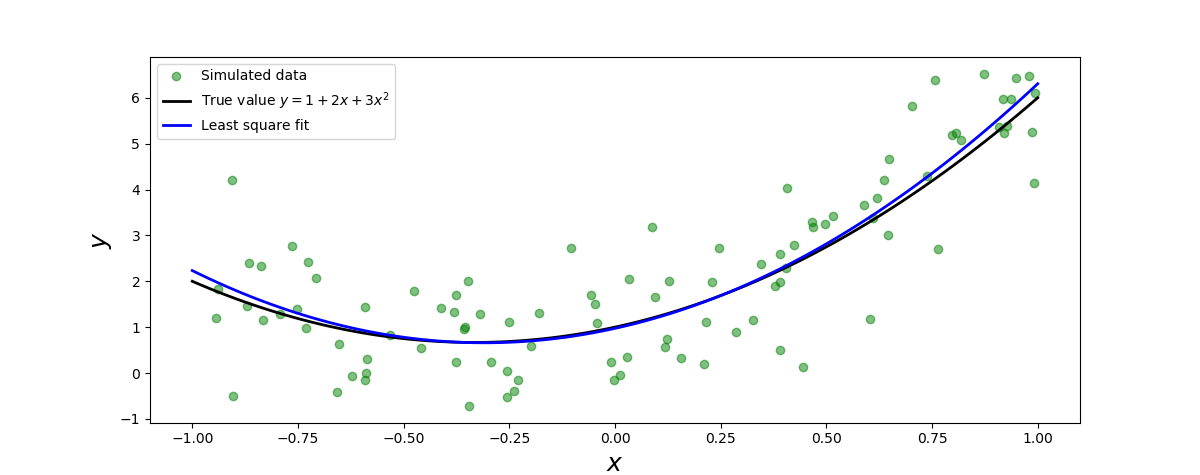
以下代码演示了如何使用 SciPy 的 la.lstsq 方法来拟合前面的示例模型,结果如下图所示。
1 | # define true model parameters |
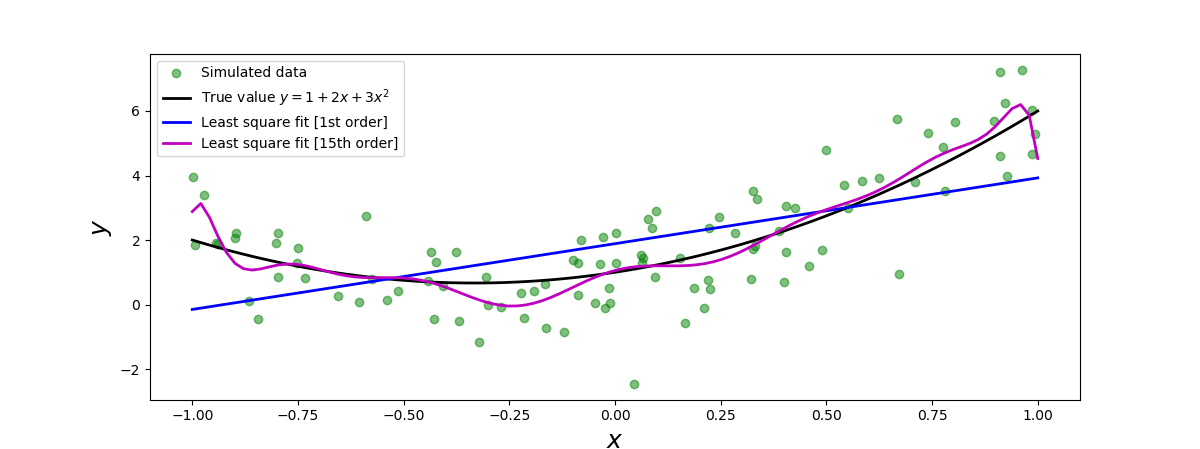
数据与模型的良好拟合显然要求用于描述数据的模型与产生数据的基础过程很好地对应。在以下示例中,我们使用与上一个示例相同数据,并将其拟合为线性模型及高阶多项式模型(最高阶数为 15)。前者对应欠拟合的情况,我们对数据使用了一个过于简单的模型,后者对应过拟合的情况,我们对数据使用了一个太过复杂的模型,因此不仅适用于模型潜在的趋势,也适应于测量噪音。使用适当的模型是数据拟合的一个重要且敏感的方面。
1 | # define true model parameters |
特征值问题
一个具有重要理论和实际意义的特殊方程组是特征值方程 $Ax = \lambda x$,其中 $A$ 是 $N \times N$ 的方阵,$x$ 是未知向量,$\lambda$ 是未知标量。这里 $x$ 是矩阵 $A$ 的特征向量,$\lambda$ 是矩阵 $A$ 的特征值。特征值方程 $Ax=\lambda x$ 与线性方程组 $Ax=b$ 非常相似,但是注意这里 $x$ 和 $\lambda$ 都是未知的,因此我们不能直接应用相同的技术来求解这个方程。解特征值问题的标准方法是将方程重写为 $(A - I\lambda)x=0$,注意到对于存在非平凡解 $x \neq 0$ 的情况,矩阵 $A - I\lambda$ 必须是奇异的,其行列式必须为零,$det(A-I\lambda) = 0$。这给出了 N 阶多项式方程(特征多项式),其 N 个根给出 N 个特征值 $\{\lambda_n\}_{n=1}^n$。一旦已知了特征值,就可以使用标准的前向替换来求解方程 $(A - I\lambda_n)x_n = 0$。
SymPy 和 SciPy 中的线性代数包都包含求解特征值问题的方法。在 SymPy 中,可以使用 Matrix 类的 eigenvals 和 eigenvects 方法,它们能够计算一些符号表达式元素的矩阵的特征值和特征向量。
1 | In [83]: eps, delta = sympy.symbols('epsilon, Delta') |
特征值方法的返回值是字典,其中每个特征值是一个键,相应的值是该特定特征值的重数。这里的特征值是 $-\sqrt{\epsilon^2 + \Delta^2}$ 和 $\sqrt{\epsilon^2 + \Delta^2}$,每个特征值都是一重的。特征向量的返回值稍微复杂一些:返回一个列表,其中每个元素是包含特征值、特征值的重数和特征向量列表的元组。每个特征值的特征向量数等于重数。对于当前示例,我们可以解包特征向量返回的值,并验证两个特征向量是否正交:
1 | In [90]: (eval1, _, evec1), (eval2, _, evec2) = H.eigenvects() |
使用这些方法获得特征值和特征向量的解析表达式通常是非常理想的,但不幸的是,它仅适用于小矩阵。对于任何大于 $3 \times 3$ 的情况,即使使用 SymPy 等计算机代数系统,解析表达式通常也变得极其冗长繁琐。因此,对于较大的系统,我们必须采用完全数值化的方法。为此,我们可以使用 SciPy 线性代数包中的 la.eigvals 和 la.eig 函数。Hermitian 矩阵或实对称矩阵具有实数特征值,对于这种矩阵,可以使用函数 la.eigvalsh 和 la.eigh ,这可以保证返回实数特征值。
1 | In [92]: A = np.array([[1, 3, 5], [3, 5, 3], [5, 3, 9]]) |
由于本例中的矩阵是对称的,我们可以使用 la.eigh 和 la.eigwalsh ,给出实数特征值数组。
非线性方程
在本节中,我们考虑非线性方程。如本章前面部分所述,线性方程组在科学计算中具有基础的重要性,因为它们易于求解,可以用作许多计算方法和技术中的重要构件。然而,在自然科学和工程学科中,即使不是大多数也有很多系统本质上也是非线性的。
根据定义,线性函数 $f(x)$ 满足可加性 $f(x+y) = f(x) + f(y)$ 和齐次性 $f(\alpha x) = \alpha f(x)$,它们可以写在一起构成叠加原理 $f(\alpha x + \beta y) = \alpha f(x) + \beta f(x)$。这给出了线性的精确定义。相反,非线性函数是不满足这些条件的函数。因此非线性是一个更广泛的概念,函数可以以许多不同的方式非线性。但是,一般而言,包含变量大于 1 次幂的表达式是非线性的。例如,$x^2+x+1$ 是非线性的。
一个非线性方程总是可以写成$f(x) = 0$ 形式,其中 $f(x)$ 是一个非线性函数,我们寻找使 $f(x) = 0$ 的 x 的值。这个 x 被称为函数 $f(x)=0$ 的根,因此方程求解通常被称为求根。与前一部分相比,在本节中,除了单方程和方程组外,还需要区分单变量方程和多变量方程。
单变量方程
单变量函数是一个仅依赖于单个变量的函数 $f(x)$,其中 x 是一个标量,相应的单变量方程的形式为 $f(x) = 0$。这种方程式的典型例子是多项式,如 $x^2 -x +1 = 0$,以及包含基本函数的表达式,如 $x^3 - 3sin(x) = 0$ 和 $exp(x) -2 = 0$。和线性系统不同,不存在一般的方法来确定非线性方程有一个解或多个解,或给定的解是唯一的。
由于存在大量可能的情况,因此很难开发一种用于求解非线性方程的完全自动方法。从分析的角度来看,只有特殊形式的方程才可以精确求解。例如,高达 4 阶的多项式以及某些特殊情况下的高阶也可以通过分析方法求解,包含三角函数和其他基本函数的一些方程式也可以通过分析方法求解。在 SymPy 中,我们可以使用 sympy.solve 函数来求解许多可解析的单变量非线性方程。如,要解标准二次方程 $a + bx + cx^2 = 0$,我们可以:
1 | In [97]: x, a, b, c = sympy.symbols("x, a, b, c") |
该解确实是解这个方程的众所周知的公式。同样的方法可以用来解决一些三角方程:
1 | In [99]: sympy.solve(a*sympy.cos(x) - b*sympy.sin(x), x) |
但是,一般情况下,非线性方程通常没有解析解。如,包含多项式表达式和基本函数(如 $sin(x) = x$)的方程通常是超越的,没有代数解。如果我们尝试使用 SymPy 来求解这样的等式,我们会以异常的形式获得错误:
1 | In [100]: sympy.solve(sympy.sin(x)-x, x) |
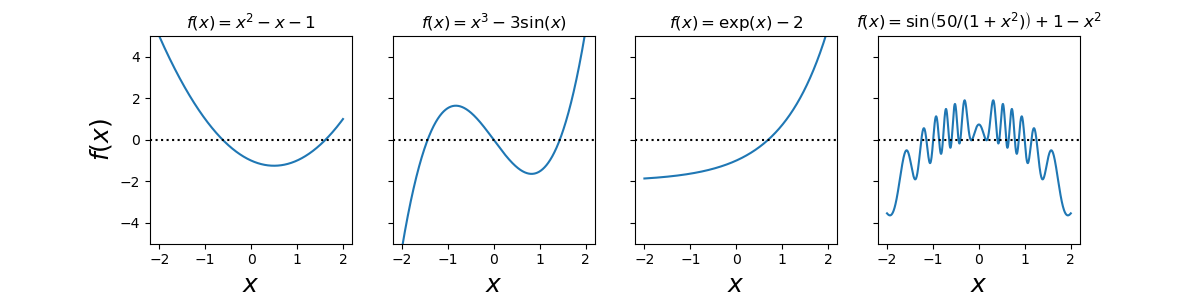
在这种情况下,我们需要采用各种数值技术。将绘制函数作为第一步,通常非常有用。这可以给出关于方程解的数量及其大概位置的重要线索。当应用数值技术找到方程根的良好近似值时,这些信息往往是必需的。例如,考虑下面的例子,它绘制了四个非线性函数。从这些图中,我们可以立即得出结论:从左到右,函数有两个、三个、一个和大量的根(至少在绘制的区间)。
1 | x = np.linspace(-2, 2, 1000) |
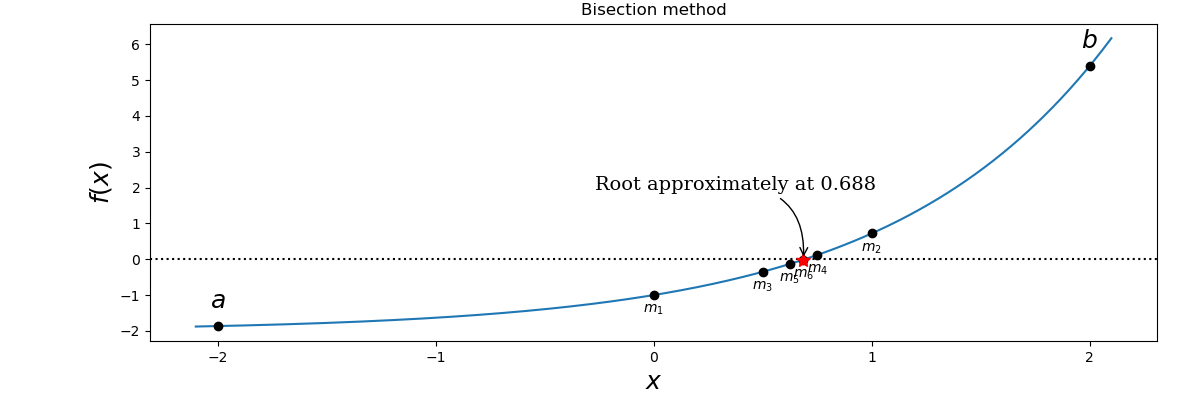
为了找到方程根的近似位置,我们可以应用数值求根的许多技术中的一种,这种技术通常应用了迭代方案,其中函数在连续点处被评估,直到缩小到解所需的精度。二分法和牛顿法是说明求根方法的基本思想的两种标准方法。
二分法需要一个起始间隔 [a,b],使得 f(a) 和 f(b) 具有不同的符号。这保证在此间隔内至少有一个根。在每次迭代中,在 a 和 b 之间的中间点 m 处计算该函数,若 a 和 m 处函数的符号不同,则为下一次迭代选择新的区间 [a, b=m]。否则,为下一次迭代选择区间[a=m, b]。这保证了在每次迭代中,函数在区间的两个端点处具有不同的符号,且在每次迭代区间减半,并因此朝着方程的根的方向处收敛。
1 | # define a function, desired tolerance and starting interval [a, b] |
另一种求根的标准方法是牛顿法,其收敛速度快于前面讨论的二分法。二分法只使用每个点处函数的符号,牛顿法使用实际函数值来获得非线性函数的更准确的近似值。特别是,它的一阶泰勒展开近似于 $f(x+dx) = f(x) + dx f^{'}(x)$,这是一个线性函数,根很容易被发现是 $x - f(x)/f^{'}(x)$。当然,这并不是函数 $f(x)$ 的根,但是在很多情况下,函数根的良好近似。通过迭代 $x_{k+1} = x_k - f(x_k)/f^{'}(x_k)$,我们可以逼近函数的根。这种方法的一个潜在问题是,$f^{'}(x_k)$ 可能在某点 $x_k$ 处为零。这种特殊情况必须在这种方法的实际实现中进行处理。
1 | # define a function, desired tolerance and starting point xk |
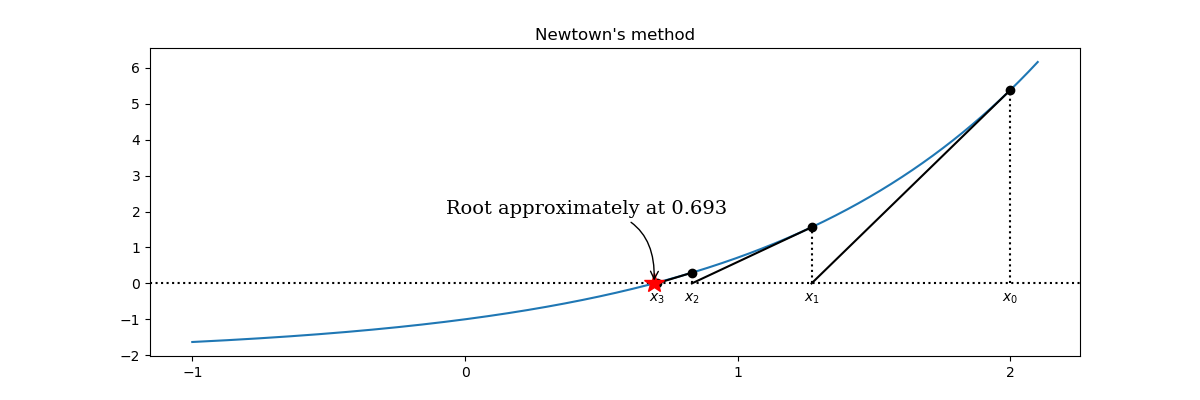
牛顿法的一个潜在问题是它需要函数值和函数导数的值。在前面的例子中,我们使用 SymPy 来符号化地计算导数。在所有数值实现中,这当然是不可能的,导数的数值近似是必要的,这又需要进一步的函数计算。牛顿法的一种变体,割线法,绕过了求函数导数的要求,它使用函数的两个之前的计算值来获得函数当前的线性近似值,该近似值可用于计算根的新估计值。割线法的迭代公式是 $x_{k+1} = x_k - f(x_k) \frac{x_k - x_{k-1}}{f(x_k) - f(x_{k-1})}$。这只是牛顿法基本思想的许多变体和可能的改进中的一个。最先进的数值求根实现,通常使用牛顿方法的二分法或二者组合的基本思想,还有各种改进策略(如,函数的高阶插值)来实现更快的收敛。
SciPy 优化模块提供了多种数值求根函数。optimize.bisect 和optimize.newton 函数实现了二分法和牛顿法的变体。optimize.bisect 有三个参数:第一个是 Pytho n函数(如 lambda 函数),它表示需要求根的数学函数,第二个和第三个参数是执行二分法的时间间隔。请注意,如前所述,函数的符号必须在 a 和 b 处不同,才能使用二分法。使用 optimize.bisect 函数,我们可以计算方程 $exp(x) -2 = 0$ 的根,
1 | In [102]: optimize.bisect(lambda x: np.exp(x) - 2, -2, 2) |
只要 f(a) 和 f(b) 确实有不同的符号,就可以保证在区间 [a,b] 内给出一个根。相比之下,牛顿法的函数 optimize.newton 将函数作为第一个参数,并将该函数的根作为第二个参数进行初始猜测。也可以使用 fprime 关键字参数来指定函数的导数。如果给定 fprime,则使用牛顿法,否则使用割线法。
1 | In [103]: x_root_guess = 2 |
请注意,使用此方法,如果函数具有多个根,则我们无法控制对正在计算哪个根。不能保证函数返回的根是最接近最初猜测的根。
SciPy 优化模块为求根提供了额外的函数。具体而言,optimize.brentq 和 optimize.brenth 函数是二分法的变体,也能在函数符号改变的区间工作。 optimize.brentq 函数通常被认为是 SciPy 中首选的全方位求根函数。
1 | In [108]: optimize.brentq(lambda x: np.exp(x) - 2, -2, 2) |
请注意,这两个函数将表示为 Python 函数的方程作为第一个参数,并将符号更改区间的下限值和上限值作为第二个参数和第三个参数。
非线性方程组
与线性方程组相比,我们通常不能将非线性方程组写成矩阵向量乘法形式。相反,我们将多元非线性方程组表示为向量值(vector-valued)函数,如 $f:\Bbb R^N \to \Bbb R^N$,它将一个 N 维向量映射到另一个 N 维向量。多变量方程组比单变量方程式要复杂得多,部分原因是有太多可能的行为。因此,没有严格保证收敛于解的方法,如单变量非线性方程的二分法,存在的方法比单变量情况下计算要求更高,特别是变量数增加时。
并非所有讨论单变量方程求解的方法都可推广到多变量情况。特别是二分法不能直接推广到多元方程组。然而,牛顿法可以推广到多元方程组,在这种情况下,迭代公式为:$x_{k+1}=x_k - J_f(x_k)^{-1}f(x_k)$ 其中 $J_f(x_k)$ 是函数 f(x) 的雅可比(Jacobian)矩阵,其元素为 $[J_f(x_k)]_{ij} = \partial f_i(x_k) / \partial x_j$。不需要求雅可比矩阵的逆,只需求解线性方程组 $J_f(x_k) \delta x_k = - f(x_k)$ 就足够了,并用 $x_{K+1} = x_k + \delta x_k$ 更新 $x_k$。像单变量方程系统牛顿法的割线法变体一样,也有多变量方法的变体,通过从函数先前的计算中估计函数当前值以避免计算雅可比矩阵。Broyden 法是一个例子。在 SciPy 优化模块中,broyden1 和 broyden2 提供了两种使用雅可比矩阵的不同近似值 Broyden 法的实现,函数 optimize.fsolve 提供了一种类牛顿法的实现,可以指定雅可比行列式。这些函数都有一个类似的函数签名:第一个参数是 Python 函数,它表示要解的方程,该方程应该将 NumPy 数组作为第一个参数,并返回一个相同形状的数组。第二个参数是 NumPy 数组形式的解的初始猜测。 optimize.fsolve 函数还包含一个可选的关键字参数 fprime,该参数用于提供返回 $f(x)$ 的雅可比矩阵的函数。另外,所有这些函数都有大量可选的关键字参数来调整它们的行为。
例如,考虑下面的两个多元非线性方程组:
$$
\begin{cases}
y - x^3 - 2x^2 + 1 & = 0 \
y + x^2 -1 & = 0
\end{cases}
$$
这可以用向量值函数 $f([x_1, x_2]) = [x_2 - x_1^3 - 2x_1^2 +1, x_2 + x_1^2 -1]$ 来表示。为了使用 SciPy 来求解这个方程组,我们需要将 $f([x_1, x_2])$ 定义为 Python 函数并调用。
1 | In [7]: def f(x): |
optimize.broyden1 和 optimize.broyden2 可以用类似的方式使用。要指定 optimize.fsolve 的雅可比矩阵,我们需要定义一个函数来计算给定输入向量的雅可比行列式。这里我们可以使用 SymPy 推导:
1 | In [9]: x, y = sympy.symbols('x, y') |
然后我们可以很容易地将它作为一个可以传递给 optimize.fsolve 函数的 Python 函数来实现:
1 | In [13]: def f_jacobian(x): |
与的变量非线性方程系统的牛顿法一样,解的初始猜测是重要的,不同的初始猜测可能会导致找到不同的解。不能保证找到任何特定的解,尽管初始猜测与真实解的接近程度通常与该特定解的收敛性相关。如果可能的话,绘制需要求解的方程的图像是一种很好的方法,可以直观地显示解的数量及其位置。例如,下面的代码演示了如何使用 optimize.fsolve 函数不同的初始猜测来找到需要求解方程组中的三种不同解。
1 | def f(x): |
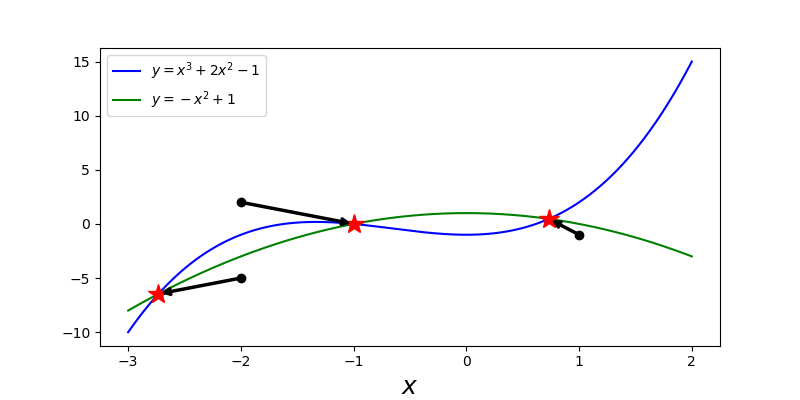
通过系统地求解具有不同初始猜测的方程组,我们可以建立不同初始猜测如何收敛到不同解的可视化图形。这是下面的代码示例中完成的。
1 | def f(x): |
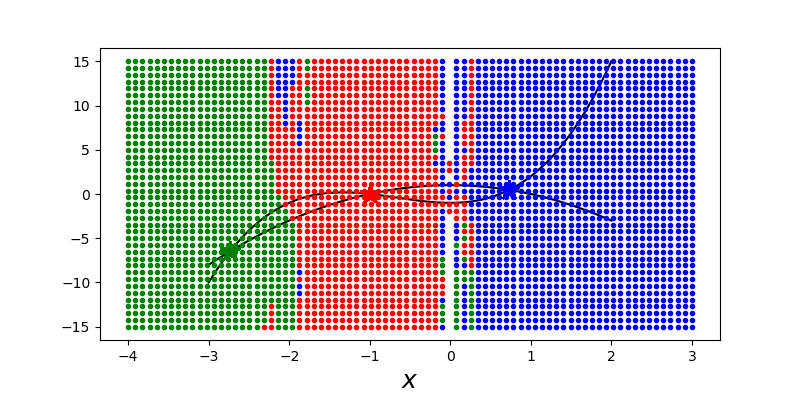
这个例子证明,即使对于相对简单的例子,收敛到不同解的初始猜测区域也是高度非平凡的,且还存在初始猜测的缺失点,对于这些缺失点,算法不能收敛到任何解。非线性方程求解是一项复杂的任务,可视化在理解特定问题的特性时往往是一个有价值的工具。