生成对抗网络(GANs)
本文介绍了生成对抗网络的起源与发展,并分析了其面临的挑战。
GANs简介
深度学习(deep learning)已经引发了一场深刻的变革,甚至已经被应用于许多实际任务,如图像分类(He et al. 2016)、目标检测(Ren et al. 2015)和图像分割(Long et al. 2015)。这些任务都属于监督学习(supervised learning)的范围,这意味着为学习过程提供大量的标记数据。然而,与监督学习相比,无监督学习(unsupervised learning)在深度学习中效果不明显。生成模型(generative modeling)是无监督学习中的一个典型问题,其目标是学习训练数据的分布,然后通过从学习的分布中采样来生成新的数据。生成模型通常比监督学习任务更困难,因为生成模型的学习标准是难以处理的(Goodfellow et al. 2016)。对于监督学习任务,给出了输入和输出之间对应的映射信息,监督学习模型只需要学习如何将映射信息编码到神经网络(neural networks)中。相比之下,对于生成模型,输入(通常是噪声向量)和输出(训练数据)之间的对应关系是未知的,生成模型必须学会如何有效地安排(arrange)输入和输出之间的映射。
根据神经层(neural layers)之间的相互作用是有向的(directed)还是无向的(undirected),生成模型可以分为两类,无向生成模型和有向生成模型。无向生成模型包括受限玻尔兹曼机(Restricted Boltzmann Macine,RBM)(Hinton and Salakhutdinov 2006)和深度玻尔兹曼机(Deep Boltzmann Machine,DBM)(Salakhutdinov and Hinton 2009)。无向生成模型通常存在难以处理的配分函数(partition function)问题,用于逼近它的技术限制了它们的有效性。最近,有向生成模型已经流行,并且已经提出了许多强大的模型,例如神经自回归分布估计器(Neural Autoregressive Distribution Estimator,NADE)(Larochelle and Murray 2011)和变分自编码器(Variational Autoencoder,VAE)(Kingma and Welling 2013)。无向和有向生成模型的例子如图1.1所示((a)无向生成模型,(b)有向生成模型)。
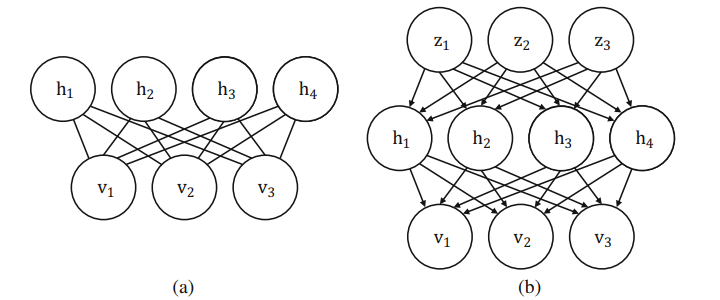
有向生成模型通常包含一个前馈网络(feedforward network),该网络将潜变量(latent variables)$z$转换为观测样本$x$,如图1.1b所示。潜变量$z$通常从简单分布(如高斯分布)中采样获得。我们可以把有向生成模型的思想看作通过前馈网络将$z$上的简单分布映射到$x$上的复杂(观察到的)分布。
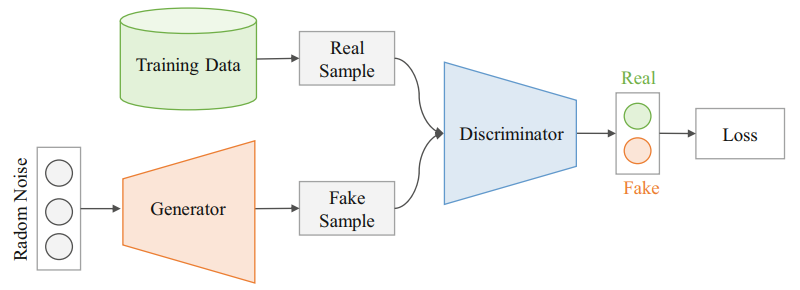
生成对抗网络(Generative Adversarial Networks, GANs)(Goodfellow et al. 2014)是一种有向生成模型。GANs可以生成非常逼真的图像。GANs的框架如图1.2所示。GANs由两个网络组成:生成器(generator)和鉴别器(discriminator)。生成器是有向生成模型中的典型前馈网络,它将潜变量$z$映射到观察样本(observed samples)$x$。鉴别器是一个分类器,用于区分生成器生成的真实样本和虚假样本。生成器和鉴别器是对立训练的:鉴别器旨在区分真实样本和虚假样本,生成器试图生成尽可能真实的虚假样本,以使鉴别器相信虚假样本来自真实数据。
GANs是最成功的生成模型之一,甚至成为许多计算机视觉和图形任务的基础。如果任务是输出高质量的图像,GANs可以帮助提高图像质量。一般的想法是添加一个鉴别器,并将GANs损失(loss)纳入任务目标。GANs已经被应用于许多特定的任务,例如图像超分辨率(image super-resolution)(Leding et al. 2017)、文本到图像合成(text to image synthesis)(Reed et al. 2016)和图像到图像翻译(image-to-image translation)(Isola et al. 2017)。
表1.1列出了鉴别器和生成器的输入和输出。鉴别器是一个典型的分类器,它预测输入图像是真实的还是虚假的(即,推测数据是从训练数据或从生成器中得到)。生成器从随机向量开始,并将向量映射到图像(通常通过一些反卷积层(transposed convolutional layers))。请注意,生成器的损失来自鉴别器,因此生成器可以知道鉴别器的行为。如果鉴别器能够正确区分虚假图像,生成器会尝试改进该图像。如果生成器能够产生更高质量的虚假图像,鉴别器就能够更好地鉴别该虚假图像,更好的鉴别器允许生成器进一步改进。因此,生成器最终可以生成非常逼真的图像。
--- |
鉴别器 | 生成器 |
|---|---|---|
| 输入 | 来自训练数据的真实图像或来自生成器的虚假图像 | 随机噪声向量 |
| 输出 | 输入为真实图像的概率 | 虚假图像 |
| 损失 | 将真实图像分类为“真实”类别,将虚假图像分类为“虚假”类别 | 鉴别器将虚假图像分类为“真实”类别 |
GANs训练的细节如算法1所示。生成器和鉴别器交替更新。 更新生成器时,鉴别器的参数是固定的,反之亦然。 鉴别器的目的是使分类误差(如,二值交叉熵损失(binary cross-entropy loss))最小化。 对于生成器,其目的是欺骗鉴别器使其对虚假图像做出错误的判断。因此,我们可以设置生成器的目标为使鉴别器的分类误差最大化。

GANs面临的挑战
虽然GANs取得了巨大的成功,但仍然面临三大挑战。第一个挑战是图像质量。许多研究试图改善GANs的图像质量(Radford et al. 2015; Denton et al. 2015; Huang et al. 2017; Salimans et al. 2016; Odena et al. 2016; Arora et al. 2017; Berthelot et al. 2017; Zhang et al. 2018; Brock et al. 2018; Jolicoeur-Martineau 2018)。Denton et al. 2015提出了深度卷积GANs(Deep Convolutional GANs,DCGANs),这是第一个成功地将卷积层引入GANs体系结构的。Denton et al. 2015提出了GANs拉普拉斯金字塔(Laplacian pyramid of GANs,LAPGANs),其中构造拉普拉斯金字塔以基于低分辨率图像生成高分辨率图像。Karras et al. 2017提出了一种新的训练方法,称为渐进训练(progressive training),首次以1024x1024分辨率生成逼真的图像。Brock et al. 2018指出,GANs可以通过扩大批大小(batch size)和每一层中的通道数量显著受益,所提出的BigGANs大大提高了在复杂数据集,如,ImageNet(Russakovsky et al. 2015)上的性能。虽然GANS可以生成甚至人类也无法区分的照片级逼真的(photorealistic)图像,但它仅限于一些目标高度“模板化”、以小边距为中心的(centered with small margins)简单数据集,如人脸数据集。对于场景数据集等复杂数据集,GANs的性能仍然有限,人们可以很容易地将生成的图像与真实图像区分开来。
第二个挑战是训练稳定性。一般来说,由于模式崩溃问题(mode collapse problem)(Radford et al. 2015; Metz et al. 2016),训练GANs在实践中比较困难。模式崩溃意味着生成器可以通过仅从一种模式(即,生成非常相似的图像)生成来欺骗鉴别器。部分工作(Arjovsky et al. 2017; Nowozin et al. 2016)试图通过分析GANs的目标函数来解决这个问题。Nowozin et al. 2016提出了f-GANs,将对应于詹森-香农散度(Jensen-Shannon divergence)的原始GANs(Goodfellow et al. 2014)推广到任意类型的f-散度。Arjovsky et al. 2017提出了Wasserstein GANs(WGANs),它使用Wasserstein距离来测量生成的样本和真实样本之间的距离。正则化技术在提高GANs的训练稳定性方面也是有效的,例如梯度惩罚(gradient penalty)(Gulrajani et al. 2017)和谱归一化(spectral normalization)(Miyato et al. 2018)。Gulrajani et al. 2017提出,梯度范数上的惩罚可用于在 Wasserstein 距离上实施 Lipschitz 约束。Miyato et al. 2018提出了谱归一化,该归一化约束每层的谱范数,以控制鉴别器的 Lipschitz 常数。请注意,训练稳定性的提高通常可产生更高质量的图像。
第三个挑战是对GANs的评估(the evaluation of GANs)。Inception score(IS)(Salimans et al. 2016)和Fréchet inception distance (FID)(Heusel et al. 2017)是GANs两个广泛使用的评价指标(evaluation metrics)。IS使用预训练的分类器将图像质量与图像是高度可分类(highly classifiable)的程度相关联。FID将生成数据和真实数据的特征建模为连续的多元高斯分布,并使用Fréchet距离来测量生成数据和真实数据之间的距离。尽管IS和FID广泛使用,问题仍然存在,如,怎么使用预训练网络以及如何近似高斯分布(Borji 2019)。
参考文献
- Arjovsky M, Chintala S, Bottou L (2017) Wasserstein GAN. In: International conference on machine learning (ICML), pp 214–223
- Arora S, Ge R, Liang Y, Ma T, Zhang Y (2017) Generalization and equilibrium in generative adversarial nets (GANs). arXiv:1703.00573
- Berthelot D, Schumm T, Metz L (2017) BEGAN: boundary equilibrium generative adversarial networks. arXiv:1703.10717
- Borji A (2019) Pros and cons of GAN evaluation measures. Comput Vis Image Underst 179:41–65
- Brock A, Donahue J, Simonyan K (2018) Large scale GAN training for high fidelity natural image synthesis. arXiv:1809.11096
- Denton E, Chintala S, Szlam A, Fergus R (2015) Deep generative image models using a Laplacian pyramid of adversarial networks. In: Advances in neural information processing systems (NeurIPS), pp 1486–1494
- Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. In: Advances in neural information processing systems (NeurIPS), pp 2672–2680
- Goodfellow I, Bengio Y, Courville A (2016) Deep learning. MIT Press, Cambridge, MA
- Gulrajani I, Ahmed F, Arjovsky M, Dumoulin V, Courville A (2017) Improved training of Wasserstein GANs. In: Advances in neural information processing systems (NeurIPS), pp 5767–5777
- He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Computer vision and pattern recognition (CVPR), pp 770–778
- Heusel M, Ramsauer H, Unterthiner T, Nessler B, Hochreiter S (2017) GANs trained by a two time-scale update rule converge to a local nash equilibrium. In: Advances in neural information processing systems (NeurIPS), pp 6626–6637
- Hinton G, Salakhutdinov R (2006) Reducing the dimensionality of data with neural networks. Science 313(5786):504–507
- Huang X, Li Y, Poursaeed O, Hopcroft J, Belongie S (2017) Stacked generative adversarial networks. In: Computer vision and pattern recognition (CVPR), pp 5077–5086
- Isola P, Zhu J-Y, Zhou T, Efros AA (2017) Image-to-image translation with conditional adversarial networks. In: Computer vision and pattern recognition (CVPR), pp 5967–5976
- Jolicoeur-Martineau A (2018) The relativistic discriminator: a key element missing from standard GAN. arXiv:1807.00734
- Karras T, Aila T, Laine S, Lehtinen J (2017) Progressive growing of GANs for improved quality, stability, and variation. arXiv:1710.10196
- Kingma DP, Welling M (2013) Auto-encoding variational Bayes. arXiv:1312.6114
- Larochelle H, Murray I (2011) The neural autoregressive distribution estimator. In: International conference on artificial intelligence and statistics (AISTATS), pp 29–37
- Ledig C, Theis L, Huszar F, Caballero J, Cunningham A, Acosta A, Aitken A, Tejani A, Totz J, Wang Z, Shi W (2017) Photo-realistic single image super-resolution using a generative adversarial network. In: Computer vision and pattern recognition (CVPR), pp 4681–4690
- Long J, Shelhamer E, Darrell T (2015) Fully convolutional networks for semantic segmentation. In: Computer vision and pattern recognition (CVPR), pp 3431–3440
- Metz L, Poole B, Pfau D, Sohl-Dickstein J (2016) Unrolled generative adversarial networks. arXiv:1611.02163
- Miyato T, Kataoka T, Koyama M, Yoshida Y (2018) Spectral normalization for generative adversarial networks. arXiv:1802.05957
- Nowozin S, Cseke B, Tomioka R (2016) f-GAN: training generative neural samplers using variational divergence minimization. In: Advances in neural information processing systems (NeurIPS), pp 271–279
- Odena A, Olah C, Shlens J (2016) Conditional image synthesis with auxiliary classifier GANs. arXiv:1610.09585
- Radford A, Metz L, Chintala S (2015) Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv:1511.06434
- Reed S, Akata Z, Yan X, Logeswaran L, Schiele B, Lee H (2016) Generative adversarial text-toimage synthesis. In: International conference on machine learning (ICML), pp 1060–1069
- Ren S, He K, Girshick R, Sun J (2015) Faster R-CNN: towards real-time object detection with region proposal networks. In: Advances in neural information processing systems (NeurIPS), pp 91–99
- Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, Bernstein M, Berg AC, Fei-Fei L (2015) ImageNet large scale visual recognition challenge. Int J Comput Vis 115:211–252
- Salakhutdinov R, Hinton G (2009) Deep Boltzmann machines. In: International conference on artificial intelligence and statistics, pp 448–455
- Salimans T, Goodfellow I, Zaremba W, Cheung V, Radford A, Chen X, Chen X (2016) Improved techniques for training GANs. In: Advances in neural information processing systems (NeurIPS), pp 2226–2234
- Zhang H, Goodfellow I, Metaxas D, Odena A (2018) Self-attention generative adversarial networks. arXiv:1805.08318