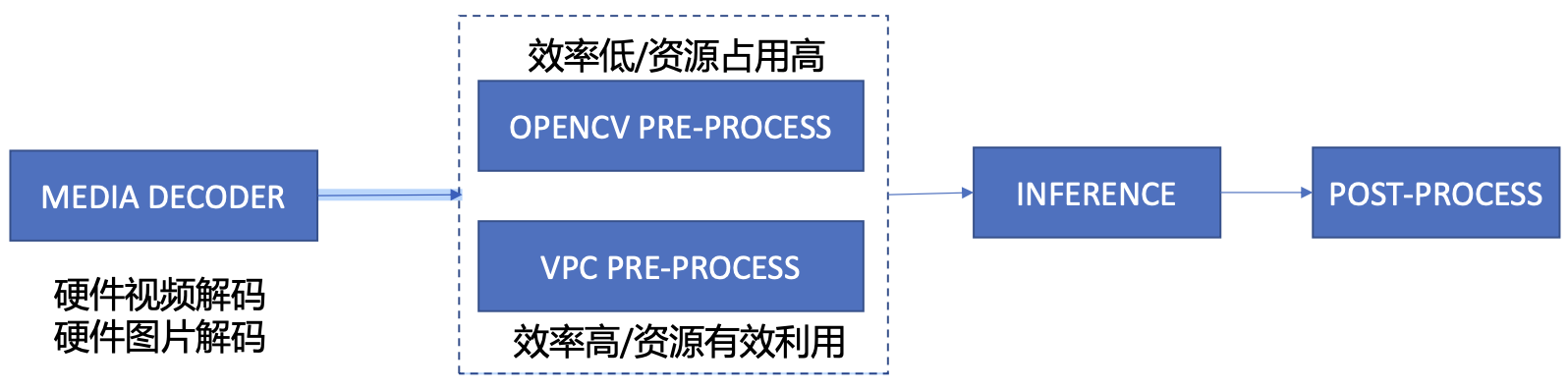
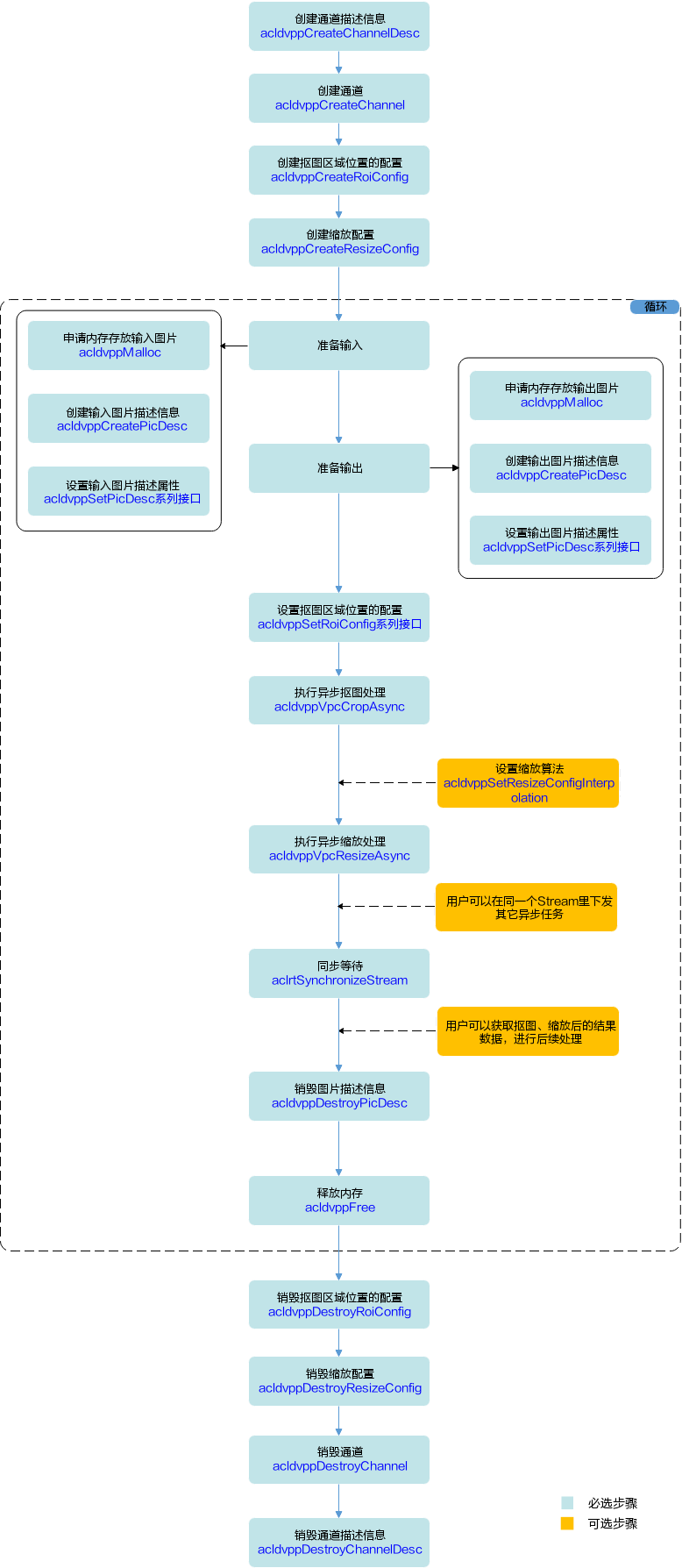
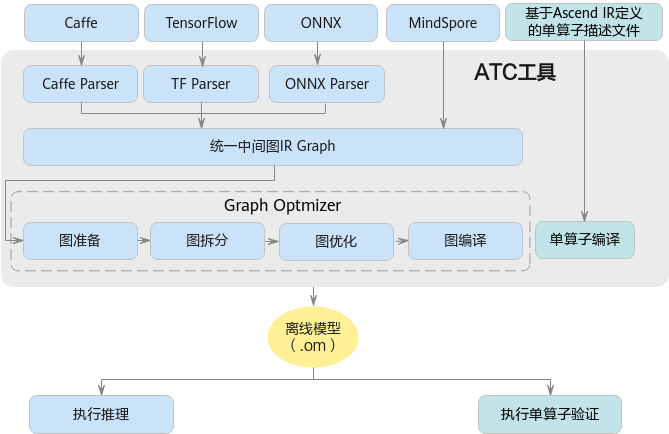
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
| #include "acl/acl.h"
#include "acl/ops/acl_dvpp.h"
aclError ret = aclInit();
ret = aclFinalize();
uint32_t device_count;
ret = aclrtGetDeviceCount(device_count);
uint32_t deviceid = 0;
ret = aclrtSetDevice(deviceid);
aclrtContext context;
ret = aclrtCreatecontext(&context,deviceid);
aclrtstream stream;
ret = aclrtCreateStream(&stream);
aclrtRunMode runmode;
ret = aclrtGetRunMode(&runmode);
int modelIdl;
model_file = "***.om";
ret = aclmdlLoadFromFileWithMem(strModelName.c_str(), &mModelID, mModelMptr, mModelMSize, mModelWptr, mModelWSize);
aclmdlDesc *modelDesc
model = aclmdlCreateDesc();
ret = aclmdlGetDesc(modelDesc,modelId);
ret = aclmdlUnload(modelId);
ret = aclmdlDestroyDesc(modelDesc);
ret = aclrtResetDevice(deviceId_);
ret = aclFinalize();
size_t modelInputSize;
void *modelInputBuffer = nullptr;
modelInputSize = aclmdlGetInputSizeByIndex(modelDesc, 0);
ret = aclrtMalloc(&modelInputBuffer, modelInputSize, ACL_MEM_MALLOC_NORMAL_ONLY);
aclmdlDataset *input_;
input_ = aclmdlCreateDataset();
aclDataBuffer *inputData = aclCreateDataBuffer(modelInputBuffer, modelInputSize);
ret = aclmdlAddDatasetBuffer(input_, inputData);
ret = aclrtMemcpy(modelInputBuffer, modelInputSize, input_host_memory_+i*3*yolo_params_.INPUT_H*yolo_params_.INPUT_W,yolo_params_.INPUT_H*yolo_params_.INPUT_W*3*sizeof(float), ACL_MEMCPY_DEVICE_TO_DEVICE);
aclmdlDataset *output_;
size_t outputSize = aclmdlGetNumOutputs(modelDesc);
output_ = aclmdlCreateDataset();
for (size_t i = 0; i < outputSize; ++i) {
size_t buffer_size = aclmdlGetOutputSizeByIndex(modelDesc, i);
void *outputBuffer = nullptr;
ret = aclrtMalloc(&outputBuffer, buffer_size, ACL_MEM_MALLOC_NORMAL_ONLY);
if(ret != 0)
{
return -2;
}
aclDataBuffer* outputData = aclCreateDataBuffer(outputBuffer, buffer_size);
ret = aclmdlAddDatasetBuffer(output_, outputData);
if(ret != 0)
{
return -2;
}
}
ret = aclmdlExecute(modelId, input_, output_);
aclDataBuffer* dataBuffer = aclmdlGetDatasetBuffer(output_, idx);
void* dataBufferDev = aclGetDataBufferAddr(dataBuffer);
size_t bufferSize = aclGetDataBufferSizeV2(dataBuffer);
void* buffer = new uint8_t[bufferSize];
aclError aclRet = aclrtMemcpy(buffer, bufferSize, dataBufferDev, bufferSize, ACL_MEMCPY_DEVICE_TO_HOST);
这里的析构是说,在每次执行完之后,都要释放掉input重新创建,因为input部分不可复用
if (input_ != nullptr)
{
for (size_t i = 0; i < aclmdlGetDatasetNumBuffers(input_); ++i)
{
aclDataBuffer* dataBuffer = aclmdlGetDatasetBuffer(input_, i);
aclDestroyDataBuffer(dataBuffer);
}
aclmdlDestroyDataset(input_);
input_ = nullptr;
}
if (output_ != nullptr) {
for (size_t i = 0; i < aclmdlGetDatasetNumBuffers(output_); ++i)
{
aclDataBuffer* dataBuffer = aclmdlGetDatasetBuffer(output_, i);
void* data = aclGetDataBufferAddr(dataBuffer);
(void)aclrtFree(data);
(void)aclDestroyDataBuffer(dataBuffer);
}
(void)aclmdlDestroyDataset(output_);
output_ = nullptr;
}
|