数值 Python: 向量、矩阵和多维数组
NumPy 是 Python 进行数值计算的核心库。在这里,我们介绍了 NumPy 的 n 维数组数据结构:ndarray 对象,并且讨论用于创建和操作数组的函数,包括从数组中提取元素的索引和切片。还讨论了使用 ndarray 对象执行计算的函数和运算符,重点介绍了向量化表达式和运算符,以便使用数组进行高效计算。
导入 NumPy 模块
1 | import numpy as np |
NumPy 数组对象
NumPy 中多维数组的主要数据结构是 ndarray 类。除了存储在数组中的数据之外,该数据结构还包含有关数组的重要元数据,例如其形状、大小、数据类型以及其他属性。有关这些属性的更详细说明,请参阅下表。ndarray docstring 中提供了具有描述的完整属性列表,在 Python 解释器中通过 np.ndarray 调出;在 IPython 控制台通过 np.ndarray? 调出。
| 属性 | 描述 |
|---|---|
| shape | 元组,值为数组中每一维(轴)的元素个数(长度) |
| size | 数组中元素的总数 |
| ndim | 维(轴)数 |
| nbytes | 存储数据所需的字节数 |
| dtype | 数组中元素的数据类型 |
示例
1 | In [3]: data = np.array([[1, 2], [3, 4], [5, 6]]) |
数据类型
下表中展示了 NumPy 支持的基本数值数据类型
| dtype | 变体 | 描述 |
|---|---|---|
| int | int8, int16, int32, int64 | 整数类型 |
| uint | uint8, uint16, uint32, uint64 | 无符号(非负)整型 |
| bool | bool | 布尔类型(True False) |
| float | float16, float32, float64, float128 | 浮点型 |
| complex | complex64, complex128, complex256 | 复数浮点型 |
NumPy 数组一旦创建其 dtype 就不能改变,但可以使用 type-casted 创建一个拷贝(也可以使用 ndarray 的 astype 属性)。
1 | In [11]: np.array([1, 2, 3], dtype=np.int) |
使用 NumPy 数组进行计算时,如果需要,数据类型可能会发生转换。
在某些情况下,根据要求,需要适当设置数据类型。考虑下面的例子:
1 | In [19]: np.sqrt(np.array([-1, 0, 1])) |
实部与虚部
1 | In [21]: data = np.array([1, 2, 3], dtype=np.complex) |
内存中数组数据的顺序
多维数组作为连续数据存储在内存中。内存段中排列数组元素的方式可以自由选择。考虑二维数组(包含行和列)的情况:一种可能的方式是按行存储,另一种是按列存储。前者被称为以行为主序格式,后者被称为以列为主序格式。在 C 中使用以行为主序格式,而 Fortran 使用以列为主序格式。使用关键字参数 order='C' (order='F')可以指定 NumPy 数组的存储格式。默认格式是以行为主序。当接口软件是 C 或 Fortran 编写时,需要注意 NumPy 数组的 C 或 F 序。
行主序或列主序只是将元素寻址索引映射到内存段中数组元素偏移量的一种特殊情况。通常,NumPy 数组属性 ndarray.strides 定义了这种映射完成的方式。strides 属性是一个长度与数组维数相同的元组。strides 中的每个值都是用于计算偏移量的因子,
当计算给定索引表达式的内存偏移量(以字节为单位)时,相应轴的索引需要与之相乘。
例如,考虑具有 shape(2, 3) 的 C-序数组 A,这是一个二维数组,沿着第一维或第二维方向分别有两个和三个元素。如果数据类型为 int32,则每个元素使用 4 个字节,数组的总内存缓冲区因此使用 2*3*4 = 24字节。因此,这个数组的 strides 属性是 (4*3, 4*1) = (12, 4),因为 A[n, m] 中 m 的每次增加,都会导致内存偏移量增加 1 项(或 4 个字节)。同样,n 的每次增加,都会导致内存偏移量增加 3 项(或 12 个字节)。另一方面,如果相同的数组以F-序存储,则 strides 将改为 (4, 8)。使用 strides
描述数组索引到数组内存偏移量的映射是很聪明的做法。因为它可以用来描述不同的映射策略,许多常见操作诸如转置,就可以通过简单地改变 strides 属性来实现,这消除了需要在内存中移动数据必要。仅仅改变 strides 属性就能产生新的 ndarray 对象,而新对象所引用的数据与原数组的相同,这种数组被称为视图(view)。 为了提高效率,NumPy 在对数组操作时努力创建视图而不是数组的副本(copy)。这很好,但更重要的是要意识到某些数组操作会产生视图而不是新的独立的数组,因此修改它们的数据也会修改原始数组的数据。
创建数组
在前一节,我们回顾了 NumPy 的基本数据结构、ndarray 类以及 ndarray 类的属性。这一节我们将关注于 NumPy 库中用来创建 ndarray 实例的函数。
在许多情况下,需生成一些元素遵循某些给定规则的数组,例如填充常量值,增加整数,统一间隔数字,随机数等。还有一些情况,可能需要从存储在文件中的数据中创建数组。需求非常多样,NumPy 库提供了一套全面的函数来生成各种类型的数组。在本节中,我们将详细介绍一些这样的函数。完整的列表可以参阅 NumPy 参考手册或通过键入 help(np)或使用自动完成 np.<Tab>。下表给出了常用数组生成函数的说明。
| 函数名 | 数组类型 |
|---|---|
| np.array | 创建一个数组,其中元素由一个类数组(array-like)对象给出,例如,它可以是 Python 列表、元组、可迭代序列或另一个 ndarray 实例。 |
| np.zeros | 创建一个指定维度和数据类型的数组,并将其填充为0 |
| np.ones | 创建一个指定维度和数据类型的数组,并将其填充为1 |
| np.diag | 创建一个对角阵,指定对角线上的值,并将其他地方填充为0 |
| np.arange | 指定开始值、结束值和增量,创建一个具有均匀间隔数值的数组 |
| np.linspace | 使用指定数量的元素,在指定的开始值和结束值之间创建一个具有均匀间隔数值的数组 |
| np.logspace | 指定开始值和结束值,创建一个具有均匀对数间隔值的数组 |
| np.meshgrid | 使用一维坐标向量生成坐标矩阵(和更高维坐标数组) |
| np.fromfunction | 创建一个数组,并用给定函数的函数值填充 |
| np.fromfile | 创建一个数组,其数据来自二进制(或文本)文件,NumPy 还提供相应的将 NumPy 数组存储在硬盘中的函数 np.tofile |
| np.genfromtxt, np.loadtxt | 创建一个数组,其数据读取子文本文件,如 CSV 文件,np.genfromtxt 也支持处理缺失值 |
| np.random.rand | 创建一个数组,其值在 (0, 1) 之间均匀分布 |
从列表或其他类数组对象创建数组
1 | In [2]: data = np.array([1, 2, 3, 4]) |
填充常量的数组
1 | In [11]: np.zeros((2, 3)) |
由增量序列填充的数组
1 | In [24]: np.arange(0.0, 10, 1) |
由对数序列填充的数组
产生在 10^0=1 到 10^2=100 之间对数分布的数组序列
1 | In [32]: np.logspace(0, 2, 5) |
Mesh-grid 数组
多维坐标网格可以使用函数 np.meshgrid 生成。给定两个一维坐标数组,就可以使用 np.meshgrid 函数生成二维坐标数组。
1 | In [33]: x = np.array([-1, 0, 1]) |
二维坐标数组常见的一种用法是评估具有两个变量(x, y)的函数。如绘制 color-map 图和等高线图。例如,评估表达式 (x+y)^2 :
1 | In [46]: Z = (X + Y)**2 |
创建未初始化的数组
1 | In [52]: np.empty(3, dtype=np.float) |
使用其他数组的特性创建数组
通常需要创建与其他数组共享特性的新数组,例如 shape 和 data type。NumPy 为此提供了一系列函数:np.ones_like、np.zeros_like、np.full_like 和 np.empty_like。典型用例是,一个函数将未指定类型和大小的数组作为参数,需要返回一个相同大小和类型的数组。如下所示:
1 | def f(x): |
创建矩阵数组
矩阵(二维数组),可通过以下方式创建
1 | In [53]: np.identity(4) |
其中,np.eye 的关键字参数 k 用于指定偏移量。
索引与切片
NumPy 数组的元素和子数组可以使用标准的方括号表示法来访问,该表示法也用于 Python 列表。在方括号内,各种不同的索引格式用于不同类型的元素选择。通常,括号内的表达式是一个元组,元组中每一项都指定了数组中相应维(轴)需要选择哪些元素。
一维数组
沿着单个轴,使用整数来选择单个元素,并且使用所谓的切片来选择元素的范围和序列。正整数用于从数组的开头索引元素(索引从 0 开始),负整数用于从数组末尾索引元素,最后一个元素用 -1 索引,倒数第二个元素用 -2 索引,依此类推。
切片的使用:符号也用于 Python 列表。 在这种表示法中,可以使用像 m: n 这样的表达式来选择一系列元素,选择的是以 m 开头并以 n-1 结尾的元素(注意不包括第 n 个元素)。 切片 m: n 也可以更明确地写为 m: n: 1,其中数字 1 表示应该选择 m 和 n 之间的每个元素。要从 m 和 n 之间每两个元素选择一个,请使用 m: n: 2,p 个元素,则使用 m: n: p。 如果 p 为负数,则元素以从 m 到 n+1 的反序返回(这意味着 m 大于 n)。有关 NumPy 阵列的索引和分片操作的概述,请参见下表。
| 表达式 | 描述 |
|---|---|
| a[m] | 选择索引为 m 的元素,其中 m 为整数 |
| a[-m] | 从列表末尾开始选择第 m 个元素,其中m是整数 |
| a[m: n] | 选择索引从 m 开始到 n-1 结束的元素 |
| a[:], a[0: -1] | 选择给定维的所有元素 |
| a[:n] | 选择索引从 0 开始 n-1 结束的元素 |
| a[m:], a[m: -1] | 选择索引从 m 开始到数组最后的所有元素 |
| a[m: n: p] | 选择索引从 m 开始 n 结束,增量为 p 的所有元素 |
| a[: : -1] | 以逆序,选择所有元素 |
1 | In [58]: a = np.arange(0, 10) |
多维数组
对于多维数组,可以在每一维运用上一节的元素选择技巧。下面是一个例子。
1 | In [61]: f = lambda m, n: n + 10 * m |
可以使用切片和整数索引的组合从这个二维数组中提取列和行:
1 | In [64]: A[:, 1] |
视图
使用切片从数组中提取的子数组是 视图 操作。也就是说,它们引用了原始数组内存中的数据。 当视图中的元素被分配新值时,原始数组的值也会因此而更新,例如:
1 | In [70]: B = A[1:5, 1:5] |
在这里,将数组 A 的值赋给数组 B,也会修改 A 中的值(因为两个数组都指向内存中的相同数据)。 提取子数组产生的是视图而不是新的独立数组,这是出于消除复制数据的这一操作从而提升性能的需求。当需要副本而不是视图时,可以使用 ndarray 实例的 copy 方法显式复制视图。
1 | In [74]: C = B[1:3, 1:3].copy() |
除了 ndarray 类的 copy 属性外,还可以使用函数 np.copy 复制数组,也可以使用带关键字参数 copy=True 的 np.array 函数来复制数组。
花式索引与布尔索引
在上一节中,我们研究了用整数和切片来索引 NumPy 数组,以提取单个元素或一定范围内元素。NumPy 还为索引数组提供了另一种方便的方法,称为花式索引。通过花式索引,可以使用另一个 NumPy 数组、Python 列表或整数序列对数组进行索引,这些数组的值将在被索引数组中选择元素。
1 | In [79]: A = np.linspace(0, 1, 11) |
这种索引方法可以沿着多维 NumPy 数组的每个轴使用。它要求用于索引的数组或列表中的元素是整数。
另一种变体是使用布尔索引数组。在这种情况下,每个元素(值为 True 或 False)指示是否从具有相应位置选择元素。也就是说,如果布尔值索引数组中的元素 n 为 True,则从索引数组中选择元素 n。如果该值为 False,则不选择元素 n。从数组中过滤元素时,此索引方法非常方便。例如,要从数组A(如上定义)中选择超过 0.5 的所有元素,我们可以:
1 | In [5]: A > 0.5 |
与使用切片创建数组不同,使用花式索引和布尔索引返回不是视图,而是新的独立数组。可以使用花式索引来为所选元素赋值:
1 | In [7]: A = np.arange(10) |
布尔索引亦是如此:
1 | In [16]: A = np.arange(10) |
下图使用可视化方式给出了索引 NumPy 数组不同方法的汇总。请注意,我们在此讨论的每种类型的索引都可以独立应用于数组的每个维度。
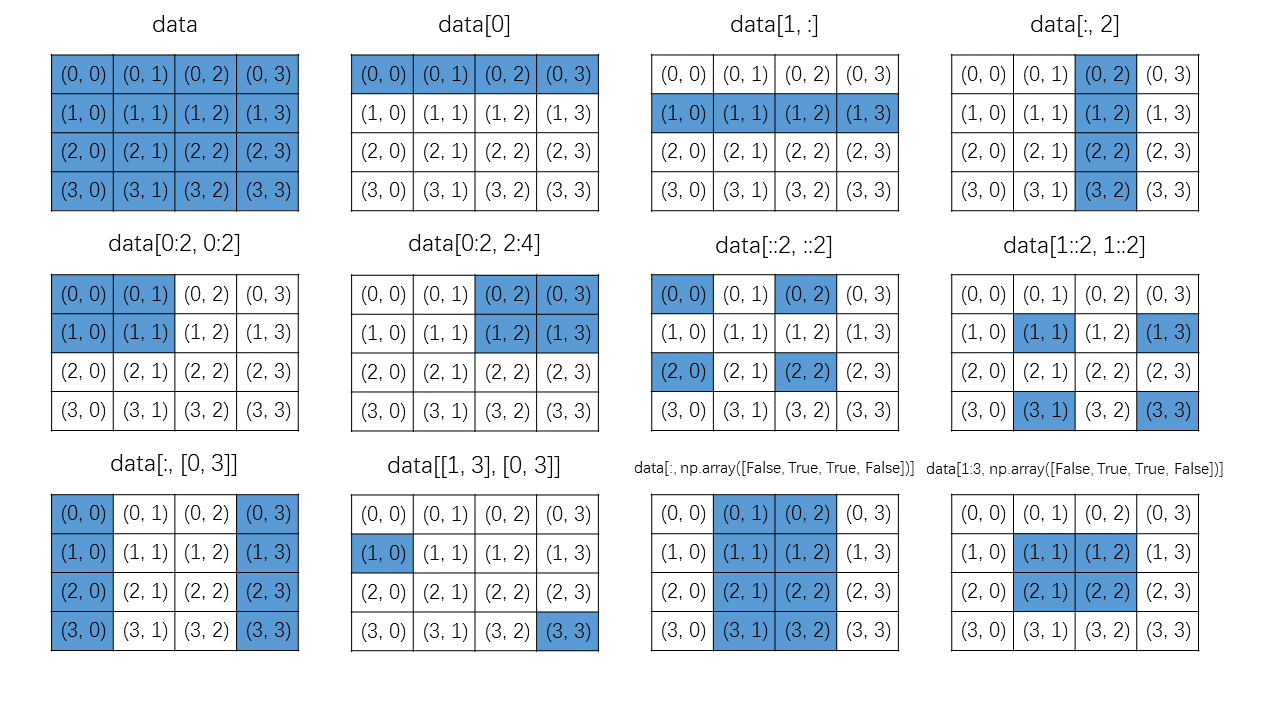
Reshaping 与 Resizing
以数组形式处理数据时,对数组进行重新排列是很常见的。下表给出了 NumPy 中一些处理重排的函数。
| 函数/方法 | 描述 |
|---|---|
| np.reshape, np.ndarray.reshape | 重排一个 N 维数组。元素的总数必须保持不变。 |
| np.ndarray.flatten | 创建一个 N 维数组的副本并将其重新解释为一维数组。 |
| np.ravel, np.ndarray.ravel | 创建一个 N 维数组的视图(如果可行,否则为副本),在该数组中将其解释为一维数组。 |
| np.squeeze | 移除长度为 1 的轴。 |
| np.expand_dims, np.newaxis | 向数组中添加长度为 1 的新轴,其中 np.newaxis 用于数组索引。 |
| np.transpose, np.ndarray.transpose, np.ndarray.T | 转置数组。 |
| np.hstack | 将一组数组水平堆栈(沿着轴 1)。 |
| np.vstack | 将一组数组垂直堆栈(沿着轴 0)。 |
| np.dstack | 深度(depth-wise)堆栈数组(沿着轴 2)。 |
| np.concatenate | 沿着给定轴堆栈数组。 |
| np.resize | 调整数组的大小。用给定的大小创建原数组的新副本。如有必要,将重复原数组以填充新数组。 |
| np.append | 将新元素添加到数组中。创建数组的新副本。 |
| np.insert | 在指定位置将元素插入新数组。创建数组的新副本。 |
| np.delete | 删除数组指定位置的元素。创建数组的新副本。 |
重排数组不需要修改底层数组数据,它只是通过重新定义数组的 strides 属性,改变了数据的解释方式。
1 | In [24]: data = np.array([[1, 2], [3, 4]]) |
所指定的新形状必须与原始数组元素总数相匹配。需要注意的是,重排数组产生的是视图,如果需要数组的独立副本,则必须显式复制(例如,使用 np.copy)。
np.ravel(及其相应的 ndarray 方法)是重排的一种特殊情况,它会折叠数组的所有维并返回扁平的一维数组,其长度与原始数组中的元素总数相对应。ndarray 的方法 flatten 具有相同的功能,但返回的是副本而不是视图。
1 | In [27]: data = np.array([[1, 2], [3, 4]]) |
虽然 np.ravel 和 np.flatten 将数组折叠为一维,但是可以通过使用 np.reshape 或 np.newaxis 关键字来引入新轴。
1 | In [32]: data = np.arange(0, 5) |
函数 np.expand_dims 也可以用来为数组添加新的维度,在上面的例子中,表达式 data[:, np.newaxis] 等价于 np.expand_dims(data, axis=1) 而 data[np.newaxis, :]相当于 np.expand_dims(data, axis=0)。这里的 axis 参数指定了插入的新轴在现有轴之中的位置。
除了重排和选择子数组之外,通常还需要将数组合并为更大的数组。NumPy 提供了函数 np.vstack 用于垂直堆栈,np.hstack 用于水平堆栈。函数 np.concatenate 提供了类似的功能,但它需要关键字参数 axis 用于指定数组要连接的轴。
1 | In [37]: data = np.arange(5) |
NumPy数组创建后,其元素的数量不能更改。使用函数 np.append、np.insert 和 np.delete 来插入、添加或移除元素,必须创建一个新数组并将数据复制到该数组中。但是由于创建新数组并复制数据的开销,通常需要给数组预分配大小。
向量化表达式
将数值数据存储在数组中的目的是为了能够使用简洁的向量化表达式来处理数据。向量化表达式的有效使用消除了许多使用显式 for 循环的必要。减少了冗长代码,具有更好的可维护性和更高的性能。
算术运算
1 | In [43]: x = np.array([[1, 2], [3, 4]]) |
如果在大小或形状不兼容的数组上执行算术运算,则会引发 ValueError 异常:
1 | In [53]: x = np.array([1, 2, 3, 4]).reshape(2, 2) |
这里数组 x 具有形状 (2, 2),而 z 具有形状 (4,) ,其无法广播到一个兼容 (2, 2) 的形式。如果 z 具有形状 (2,)、(2, 1)、或 (1, 2),那么就可以通过沿着长度为 1 的轴的方向重复数组 z 来将其形状广播到 (2, 2)。
1 | In [56]: z = np.array([[2, 4]]) |
考虑 z 具有形状 (2, 1) 的情况:
1 | In [62]: z = np.array([[2], [4]]) |
下表给出了 NumPy 数组算术运算操作符的汇总。这些运算符使用 Python 中的标准符号。
| 操作符 | 运算 |
|---|---|
+, += |
加 |
-, -= |
减 |
*, *= |
乘 |
/, /= |
除 |
//, //= |
整除 |
**, **= |
指数 |
一个或两个数组算术运算的结果是一个新的独立数组,该数组在内存中有自己的数据。评估复杂的算术运算会触发大量内存分配和复制操作,在处理大数组时,这会造成大量内存占用,从而影响性能。在这种情况下,
使用就地(in-place)操作可以减少内存占用并提高性能。
1 | In [70]: x = x + y |
这两个表达式具有相同的效果,但在第一种情况下,x 被重新分配给一个新数组,而在第二种情况下,x 的值被更新。 广泛使用就地操作往往会损害代码的可读性,因此就地操作应仅在必要时使用。
逐元素操作(element-wise)函数
NumPy 提供向量化函数,对许多基本数学函数和运算进行逐元素地评估。下表给出了 NumPy 中的基本数学函数的总结。这些函数都将单个数组(任意维)作为输入,在对应元素上应用相应的函数,并返回一个具有相同形状的新数组。输出数组的数据类型不一定与输入数组的数据类型相同。
| NumPy 函数 | 描述 |
|---|---|
np.cos, np.sin, np.tan |
三角函数 |
np.arccos, np.arcsin. np.arctan |
反三角函数 |
np.cosh, np.sinh, np.tanh |
双曲三角函数 |
np.arccosh, np.arcsinh, np.arctanh |
反双曲三角函数 |
np.sqrt |
平方根 |
np.exp |
指数 |
np.log, np.log2, np.log10 |
底为 e、2 和 10 的对数 |
1 | In [72]: x = np.linspace(-1, 1, 11) |
下表给出了逐元素数学运算的 NumPy 函数总结。
| NumPy 函数 | 描述 |
|---|---|
| np.add, np.subtract, np.multiply, np.divide | 两个 NumPy 数组的加法、减法、乘法和除法 |
| np.power | 将第一个输入参数当作为第二个输入参数的幂(逐元素地) |
| np.remainder | 除法的余数 |
| np.reciprocal | 每个元素的倒数 |
| np.real, np.imag, np.conj | 输入数组元素的实部、虚部和复共轭 |
| np.sign, np.abs | 符号值和绝对值 |
| np.floor, np.ceil, np.rint | 转换为整数 |
| np.round | 舍入到给定的小数点位数 |
有时候需要定义一个新的函数对 NumPy 数组逐元素地进行某种操作。使用现有的 NumPy 操作符和表达式是一种好的实现方式,如果没有的话,np.vectorize 不失为一个便捷的工具。考虑单位阶跃函数:
1 | In [78]: def heaviside(x): |
该函数无法用于 NumPy 数组的输入:
1 | In [81]: x = np.linspace(-5, 5, 11) |
此时可以使用 np.vectorize 来向量化:
1 | In [83]: heaviside = np.vectorize(heaviside) |
使用 np.vectorize 会相对较慢,因为会对数组中的每个元素调用原始函数。有很多其他好的实现。例如:
1 | In [85]: def heaviside(x): |
聚合函数
NumPy 提供了一组用于计算数组的聚合函数,它们将数组作为输入并将标量作为默认输出返回。诸如计算输入数组中元素的均值、标准偏差和方差以及计算数组中元素的总和和乘积的函数都是聚合函数。
下表给出了聚合函数的总结。
| NumPy 函数 | 描述 |
|---|---|
| np.mean | 数组中所有值的均值 |
| np.std | 标准偏差 |
| np.var | 方差 |
| np.sum | 所有元素的总和 |
| np.prod | 所有元素的乘积 |
| np.cumsum | 所有元素的累积和 |
| np.cumprod | 所有元素的累积乘 |
| np.min, np.max | 数组中的最小/最大值 |
| np.argmin, np.argmax | 数组中最小/最大值的索引 |
| np.all | 如果参数数组中的所有元素都不为零,则返回 True |
| np.any | 如果参数数组中的任何元素不为零,则返回 True |
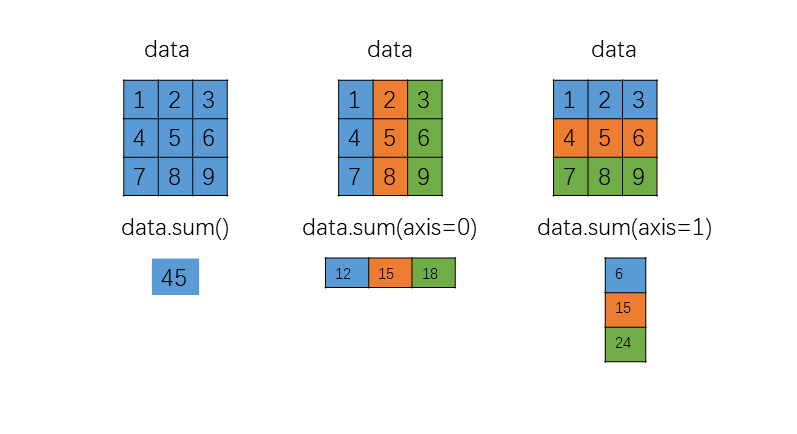
默认情况下,上表中的函数会聚合整个输入数组。使用 axis 关键字参数及对应的 ndarray 方法,可以控制数组聚合的轴。axis 参数可以是整数,用于指定要聚合的轴,也可以是整数元组,用于指定多个轴进行聚合。
1 | In [86]: data = np.random.normal(size=(5, 10, 15)) |
下图演示了聚合过程。
布尔数组与条件表达式
NumPy 数组可以与常见的比较运算符一起使用。广播规则也适用于比较运算符,如果两个数组形状兼容,则返回布尔数组。
1 | In [95]: a = np.array([1, 2, 3, 4]) |
为了在诸如 if 之类的语句中使用数组之间的比较结果,我们需要以恰当的方式聚合结果,以获得单个 True 或 False。一个常见的用法是利用 np.all 或 np.any 聚合函数:
1 | In [98]: np.all(a < b) |
布尔数组的优点是它们通常可以完全避免条件 if 语句。在算术表达式中使用布尔数组,可以以矢量化形式编写条件计算。当布尔数组与标量或其他数值类型数组一起运算时,布尔数组将转换为 0 1 数值的数组,以代替 False 和 True。
1 | In [101]: x |
这是条件计算的一个有用特性。如果我们需要定义描述具有给定高度、宽度和位置的脉冲的分段函数,可以通过将高度(标量变量)与脉冲的两个布尔数组相乘来实现该函数:
1 | In [105]: def pulse(x, position, height, width): |
在这个例子中,表达式 (x >= position) * (x <= (position + width)) 是两个布尔数组的乘法,在这种情况下,乘法运算符可看作 AND 运算符。函数 pulse 也可以使用 np.logical_and 实现:
1 | In [109]: def pulse(x, position, height, width): |
其他逻辑运算的函数,见下表。
| 函数 | 描述 |
|---|---|
| np.where | 根据条件数组的值从两个数组中选择值 |
| np.choose | 根据给定索引数组的值从数组列表中选择值 |
| np.select | 根据条件列表从数组列表中选择值 |
| np.nonzero | 返回非零元素的索引 |
| np.logical_and | 逐元素地执行 AND 操作 |
| np.logical_or, np.logical_xor | 逐元素地执行 OR/XOR 操作 |
| np.logical_not | 逐元素地执行 NOT 操作 |
给定一个布尔数组条件(第一个参数),np.where 函数从两个数组(第二个和第三个参数)中选择元素。对于条件为 True 的元素,选择第二个参数给出的数组中相应的元素,如果条件为 False,则选择第三个参数给出的数组中的元素:
1 | In [110]: x = np.linspace(-4, 4, 9) |
np.select 函数的工作原理与此类似,但它的参数是布尔条件数组的列表及相应的值数组的列表:
1 | In [112]: np.select([x < -1, x < 2, x >= 2], [x**2, x**3, x**4]) |
np.choose 将列表或数组作为第一个参数,该列表或数组的索引决定了从给定数组列表中的哪个数组中选取元素:
1 | In [113]: np.choose([0, 0, 0, 1, 1, 1, 2, 2, 2], [x**2, x**3, x**4]) |
函数 np.nonzero 返回数组索引的元组。
1 | In [115]: np.nonzero(abs(x) > 2) |
集合运算
Python 语言为管理无序唯一对象集提供了便利的 set(集合) 数据结构。NumPy 数组的类 ndarray 也可用于描述这样的集合。NumPy 提供的用于集合运算的函数可总结为下表。
| 函数 | 描述 |
|---|---|
| np.unique | 使用唯一元素创建新数组,其中每个值只出现一次 |
| np.in1d | 数组中元素是否存在另一数组中 |
| np.intersect1d | 返回给定的两个数组中都包含的元素 |
| np.setdiff1d | 返回给定的两个数组中一个数组包含而另一个数组不包含的元素 |
| np.union1d | 返回给定的两个数组的所有元素 |
1 | In [118]: a = np.unique([1, 2, 3, 4]) |
数组上的运算
下表给出了 NumPy 数组操作的总结。
| 函数 | 描述 |
|---|---|
| np.transpose, np.ndarray.transpose, np.ndarray.T | 数组的转置 |
| np.fliplr/np.flipud | 反转每行/列中的元素 |
| np.rot90 | 将前两个轴上的元素旋转 90 度 |
| np.sort, np.ndarray.sort | 对指定轴(默认为数组最后一个轴)的元素进行排序 np.ndarray 方法执行排序,修改输入数组 |
矩阵与向量运算
到目前为止,我们已经讨论了一般的 N 维数组。这种数组的主要应用之一是表示向量、矩阵和张量。在这种情况下,我们经常需要进行向量和矩阵运算,如标量(内)积、点(矩阵)乘和张量(外)积。下表给出了 NumPy 矩阵运算函数的总结。
| 函数 | 描述 |
|---|---|
| np.dot | 表示向量、数组或张量的两个给定数组之间的矩阵乘法(点乘) |
| np.inner | 表示向量的两个数组之间的标量积(内积) |
| np.cross | 表示向量的两个数组之间的叉积 |
| np.tensordot | 沿着多维数组的指定轴点乘 |
| np.outer | 表示向量的两个数组之间的外积(向量的张量积) |
| np.kron | 表示矩阵和高维数组的数组之间的 Kronecker 乘积(矩阵的张量积) |
| np.einsum | 评估多维数组的爱因斯坦求和约定(Einstein summation convention) |
为了计算矩阵 A (N * M)、B (M * P)的乘积,我们有:
1 | In [130]: A = np.arange(1, 7).reshape(2, 3) |
不幸的是,使用 np.dot 或 np.ndarray.dot 时,非平凡矩阵乘法表达式通常会变得复杂且难以阅读 例如,即使像相似变换 $A^{'}=BAB^{-1}$ 那样的相对简单的矩阵表达式,也必须用相对隐蔽的嵌套表达式来表示:
1 | In [141]: A = np.random.rand(3, 3) |
可以使用 @ 表示矩阵乘法:
1 | In [147]: Ap = B @ A @ np.linalg.inv(B) |
为了改善这一情况,NumPy 提供了另一种可选数据结构 matrix。像 A * B 这样的表达式作为矩阵乘法。它还提供了一些方便的特殊属性,如 matrix.I 表示逆矩阵,matrix.H 表示矩阵的复共轭转置。
1 | In [149]: A = np.matrix(A) |
使用 matrix 类有一些缺点,因此不鼓励使用它。反对使用 matrix 的主要意见是:像 A * B 这样的表达式与上下文相关(也就是说,如果 A * B 表示元素或矩阵乘法,它并不是十分清晰的,因为它取决于 A 和 B 的类型),另一个就是代码可读性问题。
np.asmatrix 函数以 np.matrix 实例的形式创建原始数组的视图。
1 | In [153]: A = np.asmatrix(A) |
表示向量的两个数组之间的内积(标量积)可以使用 np.inner 函数来计算:
1 | In [162]: X |
主要区别在于,np.inner 需要两个具有相同维度的输入参数,而 np.dot 可以分别采用形状为 1 * N 和 N * 1 的输入向量:
1 | In [165]: y = X[:, np.newaxis] |
内积将两个向量映射为标量,外积则将两个向量映射为矩阵。
1 | In [168]: x = np.array([1, 2, 3]) |
外积也可以使用函数 np.kron 以 Kronecker 积进行计算,与 np.outer 相反,如果输入数组具有形状 (M, N) 和 (P, Q),则输出数组具有形状 (M * P, N * Q)。 因此,对于长度为 M 和 P 的两个一维数组的情况,得到的数组具有形状 (M * P, ):
1 | In [170]: np.kron(x, x) |
为了获得对应于 np.outer(x, x) 的结果,输入数组 x 必须分别在 np.kron 的第一个和第二个参数中以形成 (N, 1) 和 (1, N) 展开:
1 | In [171]: np.kron(x[:, np.newaxis], x[np.newaxis, :]) |
通常,np.outer 函数主要将向量作为输入,np.kron 函数可用于计算任意维数组的张量积(但两个输入必须具有相同的维数)。
1 | In [172]: np.kron(np.ones((2, 2)), np.identity(2)) |
在处理多维数组时,通常可以使用爱因斯坦求和约定来简洁地表达常见数组操作,其中在表达式中多次出现某个下标(索引),则假定隐式求和。例如,两个矢量 x 和 y 之间的标量乘积可以紧凑地表示为 $x_ny_n$,并且两个矩阵 A 和 B 的矩阵乘积则表示为 $A_{mk}B_{kn}$。NumPy 提供了执行爱因斯坦求和的函数 np.einsum。它的第一个参数是索引表达式,随后是包含在表达式中的任意数量的数组。索引表达式是由逗号分隔索引的字符串,其中每个逗号分隔代表相应数组的索引。每个数组可以有任意数量的索引。例如,可以使用 np.einsum 评估标量表达式 $x_ny_n$,其索引表达式为 “n, n”,也就是说使用 np.einsum(“n,n”, x, y):
1 | In [174]: x = np.array([1, 2, 3, 4]) |
类似地,可以使用 np.einsum 和索引表达式 “mk, kn” 来评估矩阵乘法 $A_{mk}B_{kn}$:
1 | In [178]: A = np.arange(9).reshape(3, 3) |
在处理多维数组时,爱因斯坦求和约定特别方便,因为定义操作的索引表达式使得它明确地指出了执行哪个操作、沿着哪个轴执行。而使用 np.tensordot 进行的等效计算可能需要给出用于计算点积的轴。
翻译自:Numerical Python: A Practical Techniques Approach for Industry